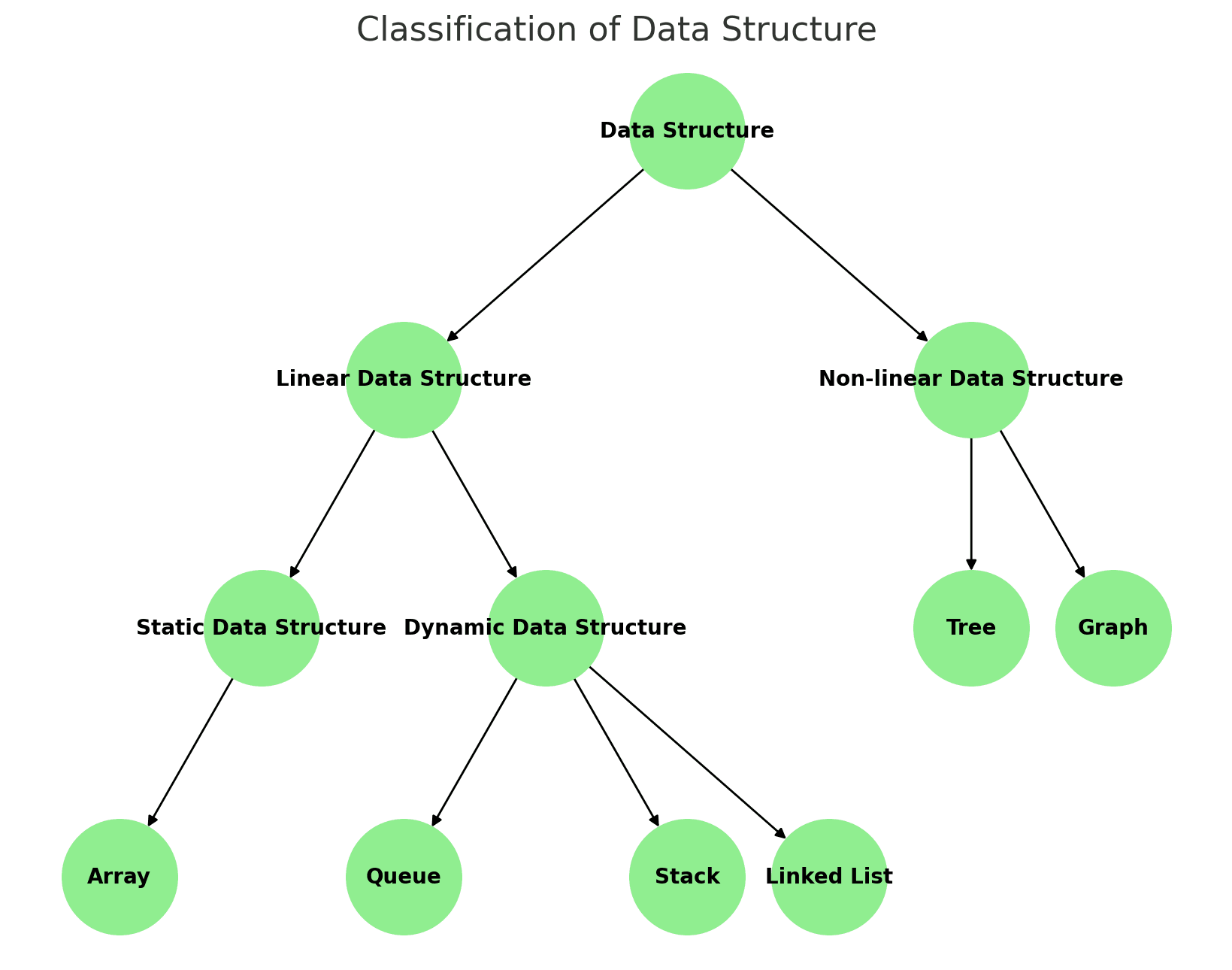
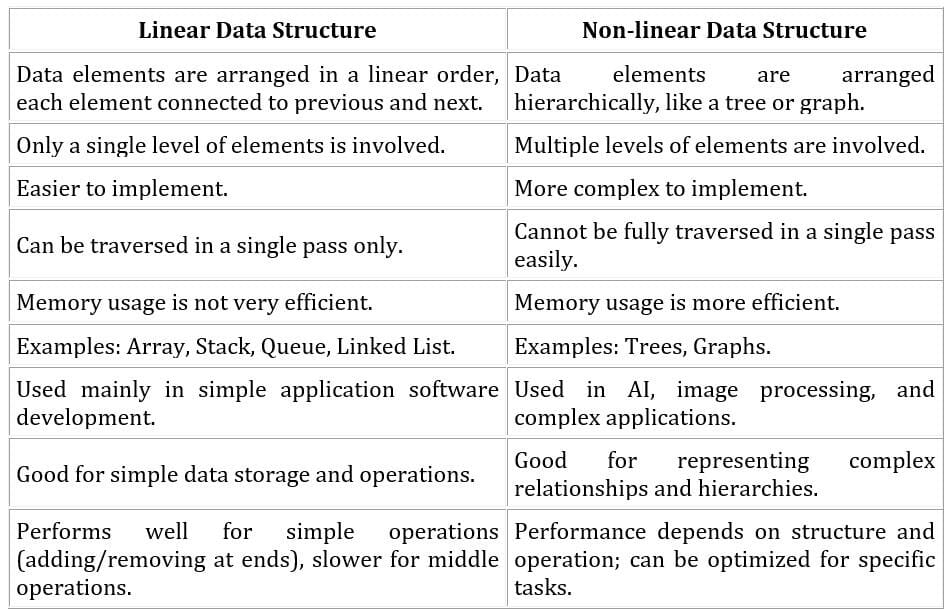
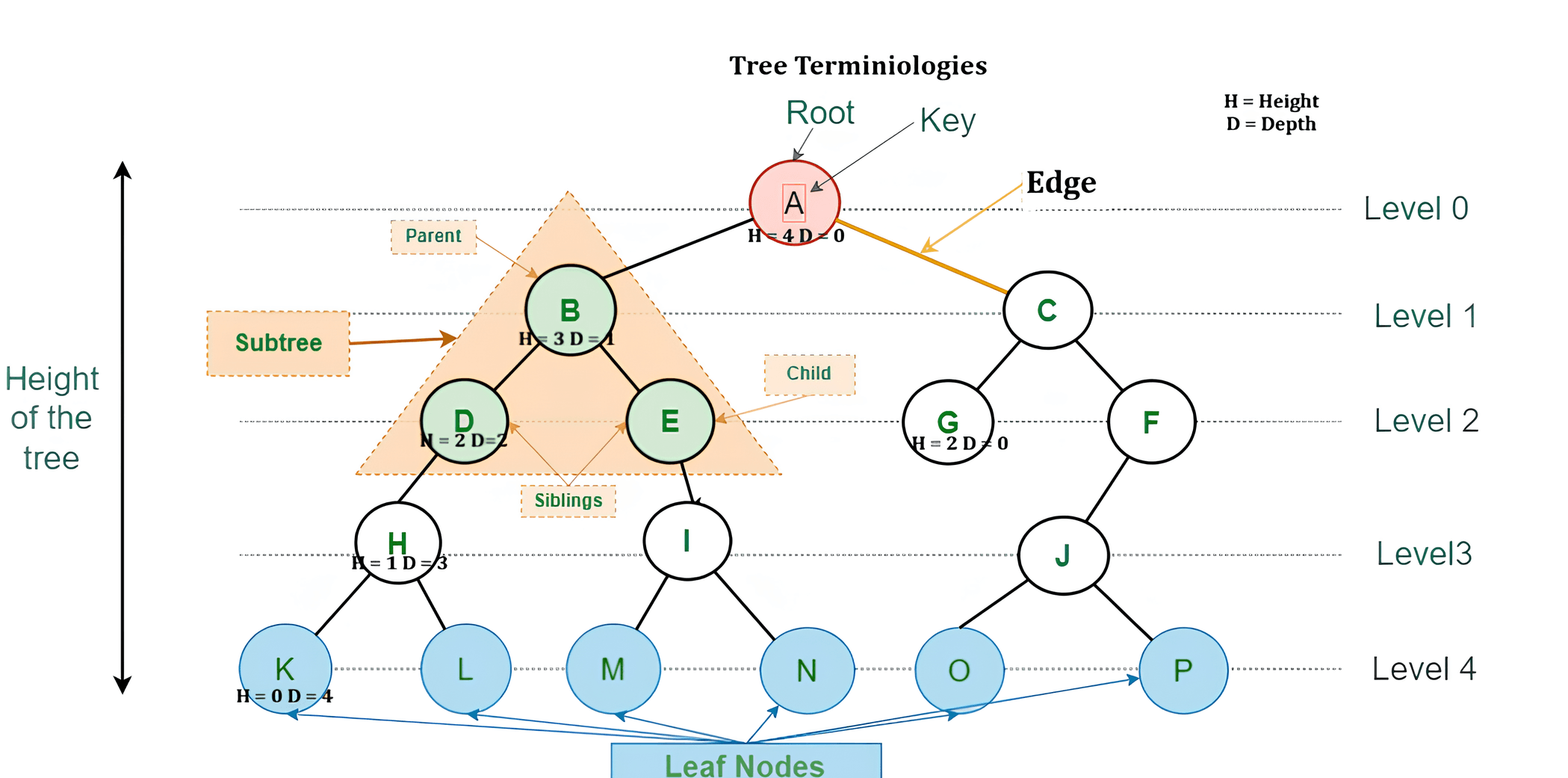
Introduction to Data Structure
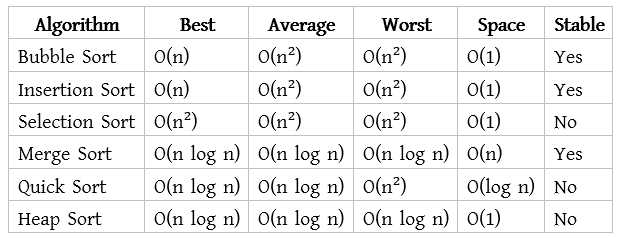
Complexity of Algorithm
Array
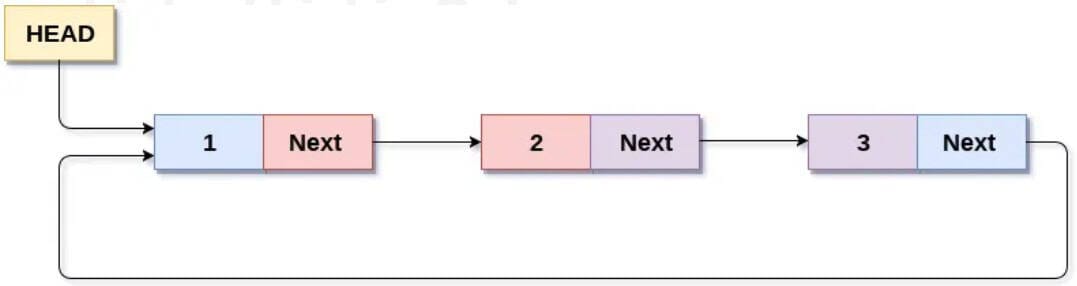
Linked List
A singly linked list is a linear collection of data items called nodes, where each node is divided into two parts.
- Data
- Link

- The first node has a special name called HEAD.
- The data part stores the data item.
- The link part stores the address of the next node.
- The last node is called the tail node.
- The linked list starts with a special pointer called the HEAD pointer and terminates with a NULL pointer.
Singly linked list হলো একটি linear collection of data items, যেগুলোকে node বলা হয়। প্রতিটি node দুইটি অংশে বিভক্ত থাকে।
- Data
- Link
- প্রথম node-টির একটি বিশেষ নাম রয়েছে, যাকে HEAD বলা হয়।
- Data part-এ data item store করা হয়।
- Link part-এ পরবর্তী node-এর address store করা হয়।
- শেষ node-টিকে tail node বলা হয়।
- Linked list একটি বিশেষ pointer দিয়ে শুরু হয় যাকে HEAD pointer বলা হয় এবং এটি NULL pointer-এ শেষ হয়।
struct node { int data; struct node *next; };
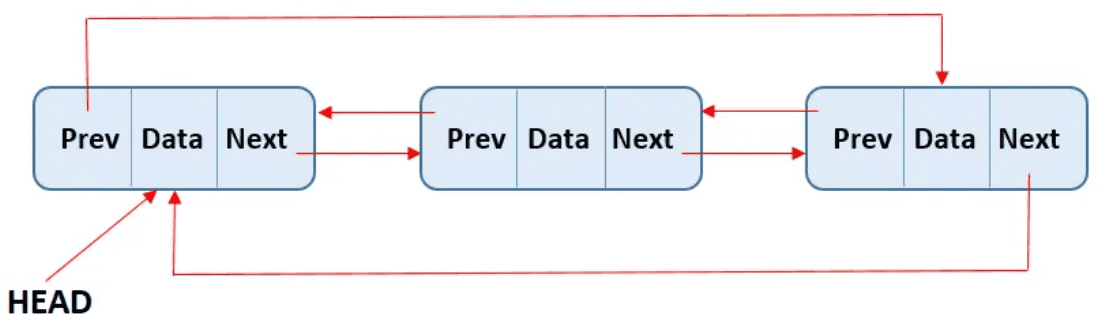
Doubly linked list is the linear collection of data item called node where each node has divided into three parts.
- previous
- data
- next

- Data part store data items.
- Next part store the address of next node
- previous part store the address of previous node.
- Doubly linked list start with special pointer called first pointer ending with last pointer.
- It allows us to perform traversing in both way “Forward & Backward”
Declaration of Doubly linked list:
struct node { int data; struct node *next; struct node *prev; }
Circular linked list is the variation of singly and doubly linked list where first node point to last node and last node point to first node
It is used when we want traversing of data no. of time without reinitialized the start pointer as well as we can visit all the nodes from any nodes.
Types of Circular linked list:
- Circular singly Linked list
- Circular doubly linked list
If the last node of singly linked list hold the address of start node then it’s called circular singly linked list.
If the last node of doubly linked list hold the address of first node and first node hold the address of last node then it’s called circular doubly linked list.
Previous Question on Linked List
| Exprsn | Stack | Postfix |
|---|---|---|
| ( | ||
| P | ( | P |
| = | ( | P = |
| 12 | ( | P = 12 |
| / | (/ | P = 12 |
| ( | (/ ( | P = 12 |
| 7 | (/ ( | P = 12 7 |
| – | (/ (- | P = 12 7 |
| 3 | (/ (- | P = 12 7 3 |
| ) | (/ | P = 12 7 3 – |
| + | (+ | P = 12 7 3 – / |
| 2 | (+ | P = 12 7 3 – / 2 |
| ) | P = 12 7 3 – / 2 + |
✔ 12 → Push onto stack → Stack: [12]
✔ 7 → Push onto stack → Stack: [12, 7]
✔ 3 → Push onto stack → Stack: [12, 7, 3]
✔ – → Pop 7 and 3, perform 7 – 3 = 4 → Push 4 → Stack: [12, 4]
✔ / → Pop 12 and 4, perform 12 / 4 = 3 → Push 3 → Stack: [3]
✔ 2 → Push onto stack → Stack: [3, 2]
✔ + → Pop 3 and 2, perform 3 + 2 = 5 → Push 5 → Stack: [5]
The evaluated value of the expression is: P = 5
Stack
When we define a stack as an Abstract Data Type (ADT), our primary focus is on the operations that can be performed on the stack, rather than how the stack is implemented internally.
The primary operations of a stack are as follows:
push(data): Adds a new element, data, onto the top of the stack.
pop(): Removes and returns the last element that was added to the stack (the topmost element).
top(): Retrieves the last inserted element from the stack without removing it, allowing you to peek at the top element.
size(): Returns the total number of elements currently in the stack.
isEmpty(): Checks if the stack is empty. Returns TRUE if the stack contains no elements, otherwise returns FALSE.
isFull(): Checks if the stack has reached its maximum capacity. Returns TRUE if the stack is full, otherwise returns FALSE.
Algorithm Insertion to Stack : PUSH operation
1. Checks if the stack is full.
2. If the stack is full, return "overflow" and exit.
3. If the stack is not full, increments top to point next
empty space.
4. Adds data element to the stack location, where top
is pointing.
5. Returns success.pseudo-code of PUSH operation
PUSH(stack, data) if stack is full: return "Overflow" // Stack is full, cannot add more elements else: top= top + 1 // Move to the next available position in the stack stack[top] = data // Add the data element at the current top position return "Success" // Data added successfully
Algorithm Insertion to Stack : POP operation
1. Checks if the stack is empty. 2. If the stack is empty, return underflow and exit. 3. If the stack is not empty, accesses the data element at which top is pointing. 4. Decreases the value of top by 1. 5. Returns success.
pseudo-code of POP operation
POP(stack) if stack is empty: return "Underflow" // Stack is empty, cannot remove elements else: data = stack[top] // Access the data element at the current top position top = top - 1 // Move the top pointer to the previous element return "Success" // Data removed successfully
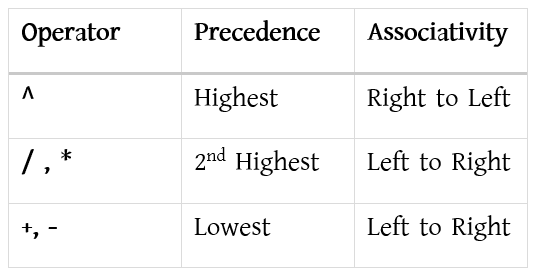
Infix expression: If operator is placed in between the operands then its called infix expression.
Infix Expression: <operand> <operator> <operand>
Example: A + B, A * B;
Prefix expression: If operator is placed before the operands then its called prefix expression.
Prefix Expression: <operator> <operand> <operand>
Example: +AB, *AB ;
Postfix expression: If operator is placed after the operands then its called postfix expression.
Postfix Expression: <operand> <operand> <operator>
Example: AB+, AB* ;
(i) (A + B) * (B * D)
(ii) (a+b)*c
(iii)a/b+c/d
(iv)(a+b*d)*(b-c)
(i) (A + B) * (B * D)
= (AB+) * (BD*)
= AB+ BD* *
(ii) (a+b)*c
= (ab+) * c
= ab+c*
(iii) a/b+c/d
= (ab/) + (cd/)
= ab/cd/+
(iv) (a+b*d)*(b-c)
=(a+(bd*))*(bc-)
=(abd*+)*(bc-)
=abd*+bc-*
(i) (A + B) * (B * D)
(ii) (a+b)*c
(iii)a/b+c/d
(iv)(a+b*d)*(b-c)
(v) ((a+b)*c)-d
(i) (A + B) * (B * D)
= (+AB) * (*BD)
= *+AB *BD
(ii) (a+b)*c
= (+ab) * c
= *+abc
(iii) a/b+c/d
= (/ab) + (/cd)
= +/ab/cd
(iv) (a+b*d)*(b-c)
=(a+(*bd))*(-bc)
=(+a*bd)*(-bc)
=*+a*bd-bc
(v) ((a+b)*c)-d
=((+ab)*c)-d
=(*+abc)-d
= – * + abcd
(i) ABD*+BC-*
(ii) ab+cd+*
(i) ABD*+BC-*
= A (B*D)+BC-*
= (A+(B*D))BC-*
=(A+(B*D))(B-C)*
=(A+(B*D))*(B-C)
(ii) ab+cd+*
= (a+b)cd+*
= (a+b) (c+d)*
= (a+b) * (c+d)
(i) -*+abcd
(ii)/+A*BD-BC
(iii)+/ab/cd
(i) -*+abcd
= -*(a+b)cd
= -((a+b)*c)d
=((a+b)*c)-d
(ii) /+A*BD-BC
= /+A(B*D)-BC
= /(A+(B*D))-BC
= /(A+(B*D))(B-C)
= (A+(B*D))/(B-C)
(iii)+/ab/cd
=+(a/b)/cd
=+(a/b)(c/d)
=(a/b)+(c/d)
Below is the algorithm to convert an infix expression to postfix notation:
- Initialize:
- Push
"("onto the Stack. - Add
")"to the end of the expressionX.
- Push
- Scan Expression
Xfrom left to right:- Repeat Steps 3 to 6 for each element of
Xuntil the Stack is empty.
- Repeat Steps 3 to 6 for each element of
- If the character is an operand:
- Add the operand directly to
Y.
- Add the operand directly to
- If the character is a left parenthesis
"(":- Push
"("onto the Stack.
- Push
- If the character is an operator:
- Repeatedly pop operators from the Stack and add them to
Ywhile the operator at the top of the Stack has equal or higher precedence than the current operator. - Push the current operator onto the Stack.
- Repeatedly pop operators from the Stack and add them to
- If the character is a right parenthesis
")":- Repeatedly pop operators from the Stack and add them to
Yuntil a left parenthesis"("is encountered. - Remove the left parenthesis from the Stack.
- Repeatedly pop operators from the Stack and add them to
- End of Expression:
- Once the entire expression is processed, the final postfix expression
Ywill be available in the output.
- Once the entire expression is processed, the final postfix expression
Example
Infix to Postfix Conversion Stack Table
A+B/C*(D+E)-F
Adding “)” at the end of expression =A+B/C*(D+E)-F)
| Scan | Stack | Postfix Expression |
|---|---|---|
| ( | ||
| A | ( | A |
| + | (+ | A |
| B | (+ | A B |
| / | (+ / | A B |
| C | (+ / | A B C |
| * | (+ * | A B C / |
| ( | (+ * ( | A B C / |
| D | (+ * ( | A B C / D |
| + | (+ * ( + | A B C / D |
| E | (+ * ( + | A B C / D E |
| ) | (+ * | A B C / D E + |
| – | (- | A B C / D E + * |
| F | (- | A B C / D E + * + F |
| ) | A B C / D E + * + F – |
Postfix expression: A B C / D E + * + F –
Below is the algorithm to evaluate a postfix expression:
- Initialize:
- Create an empty stack.
- Scan the postfix expression from left to right:
- Repeat the following steps for each symbol in the expression.
- If the symbol is an operand (a number or a variable):
- Push the operand’s value onto the stack.
- If the symbol is an operator (+, -, *, /, ^, etc.):
- Pop the top two operands from the stack.
- Let the first popped operand be
operand1and the second popped operand beoperand2. - Perform the operation:
operand2 operator operand1. - Push the result of this operation back onto the stack.
- After scanning the entire expression:
- The final result of the evaluation will be the only value remaining on the stack.
- Pop this value and return it as the result of the expression.
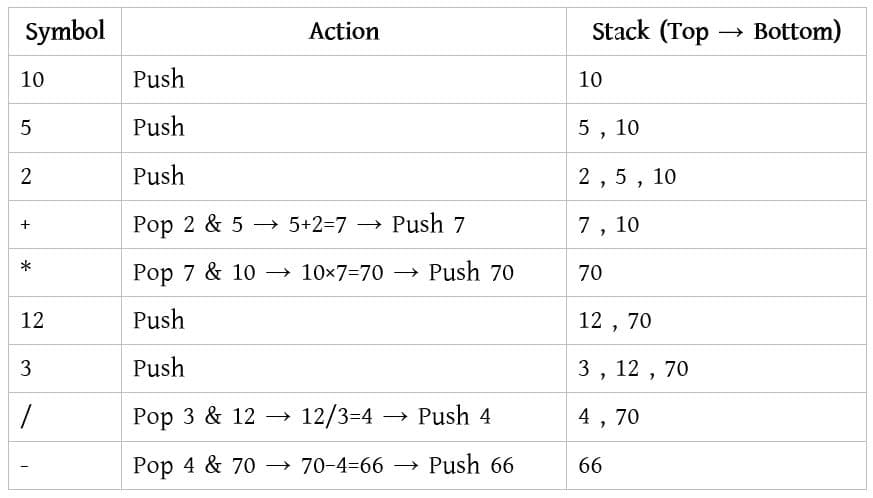
Example: P = 12 7 3 – / 2 +
✔ 12 → Push onto stack → Stack: [12]
✔ 7 → Push onto stack → Stack: [12, 7]
✔ 3 → Push onto stack → Stack: [12, 7, 3]
✔ – → Pop 7 and 3, perform 7 – 3 = 4 → Push 4 → Stack: [12, 4]
✔ / → Pop 12 and 4, perform 12 / 4 = 3 → Push 3 → Stack: [3]
✔ 2 → Push onto stack → Stack: [3, 2]
✔ + → Pop 3 and 2, perform 3 + 2 = 5 → Push 5 → Stack: [5]
The evaluated value of the expression is: P = 5
[(A+B)-{C+D}]
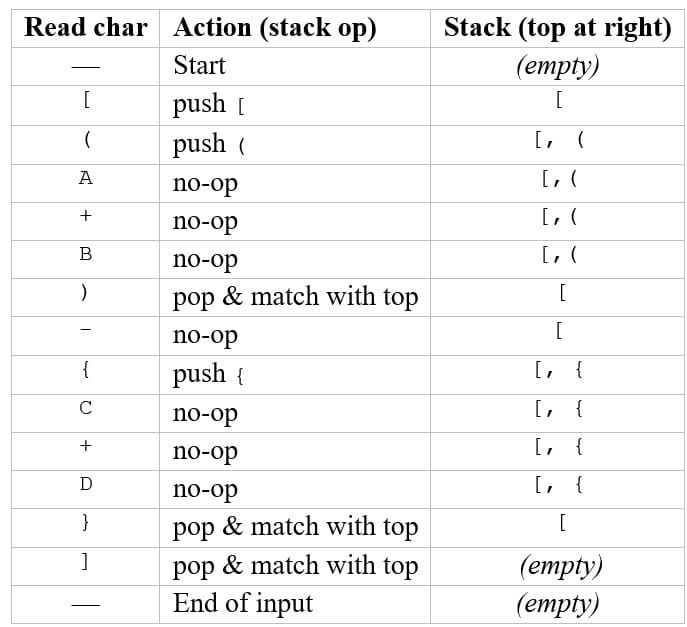
A + ( B * C − ( D / E $ F ) * G) * H
10 5 2 + * 12 3 / -
Queue
Tree Data Structure
Inorder: D B E A F C
Preorder: A B D E C F
Given
Inorder: D B E A F C
Preorder: A B D E C F
Rule
1) In Preorder, the first element is always the Root.
2) In Inorder, elements left of Root belong to Left Subtree, and elements right of Root belong to Right Subtree.
Step 1: Find Root
Preorder = A B D E C F → Root = A
Now locate A in Inorder: D B E A F C
Left(Inorder) = D B E
Right(Inorder) = F C
Step 2: Build Left Subtree of A
Left(Inorder) = D B E (3 nodes) → so next 3 nodes in Preorder after A belong to left subtree.
Preorder after A = B D E … → Left(Preorder) = B D E
Now for Left subtree:
Preorder = B D E → Root = B
Find B in Inorder: D B E
Left of B (Inorder) = D
Right of B (Inorder) = E
So B’s left child = D, B’s right child = E
Step 3: Build Right Subtree of A
Right(Inorder) = F C (2 nodes) → remaining Preorder nodes belong to right subtree.
Remaining Preorder = C F → Right(Preorder) = C F
Now for Right subtree:
Preorder = C F → Root = C
Find C in Inorder: F C
Left of C (Inorder) = F
Right of C (Inorder) = (none)
So C’s left child = F, C has no right child.
Final Constructed Binary Tree
A
/ \
B C
/ \ /
D E FGiven
Postorder Traversal: 8, 9, 6, 7, 4, 5, 2, 3, 1
Inorder Traversal: 8, 3, 9, 4, 7, 2, 5, 1, 6
Rule Used
1) In Postorder, the last element is always the Root.
2) In Inorder, elements to the left of the root belong to the left subtree and elements to the right belong to the right subtree.
Step 1: Identify Root
Postorder last element = 1 → Root of the tree is 1.
Inorder split at 1:
Left(Inorder) = 8, 3, 9, 4, 7, 2, 5
Right(Inorder) = 6
Step 2: Construct Right Subtree
Right(Inorder) has only one node → Right child of 1 is 6.
Step 3: Construct Left Subtree
Remaining Postorder (before 1) = 8, 9, 6, 7, 4, 5, 2, 3
Last element here = 3 → Root of left subtree.
Inorder split at 3:
Left of 3 = 8
Right of 3 = 9, 4, 7, 2, 5
Continuing this process recursively, the left subtree is constructed.
Final Binary Tree Structure
1
/ \
3 6
/ \
8 2
/ \
4 5
/ \
9 7Step 4: Find Height of the Tree
Height of a binary tree is the number of edges on the longest path from root to a leaf.
Longest path here is:
1 → 3 → 2 → 4 → 9
This path has 4 edges.
Final Answer
The height of the given binary tree is 4.
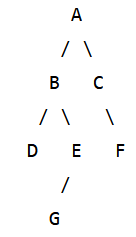 1) Write the Inorder Traversal of the above binary tree.
1) Write the Inorder Traversal of the above binary tree.2) Write the Preorder Traversal of the above binary tree.
3) Write the Postorder Traversal of the above binary tree.
D B G E A C F
Preorder Traversal:
A B D E G C F
Postorder Traversal:
D G E B F C A
Heap Data Structure
Sorting Algorithm
bubbleSort(array)
for i ← 1 to sizeOfArray − 1 do for j ← 1 to sizeOfArray − 1 − i do
if array[j] > array[j + 1] then
swap array[j] and array[j + 1]
end if end for end for
end bubbleSort
Bubble Sort (Ascending) — Step-by-step Iterations
Initial List: [30, 25, 62, 45, 7, 10]
Pass 1 (i = 1)
1) Compare 30 and 25 → swap → [25, 30, 62, 45, 7, 10]
2) Compare 30 and 62 → no swap → [25, 30, 62, 45, 7, 10]
3) Compare 62 and 45 → swap → [25, 30, 45, 62, 7, 10]
4) Compare 62 and 7 → swap → [25, 30, 45, 7, 62, 10]
5) Compare 62 and 10 → swap → [25, 30, 45, 7, 10, 62]
End of Pass 1: [25, 30, 45, 7, 10, 62]
Pass 2 (i = 2)
1) Compare 25 and 30 → no swap → [25, 30, 45, 7, 10, 62]
2) Compare 30 and 45 → no swap → [25, 30, 45, 7, 10, 62]
3) Compare 45 and 7 → swap → [25, 30, 7, 45, 10, 62]
4) Compare 45 and 10 → swap → [25, 30, 7, 10, 45, 62]
End of Pass 2: [25, 30, 7, 10, 45, 62]
Pass 3 (i = 3)
1) Compare 25 and 30 → no swap → [25, 30, 7, 10, 45, 62]
2) Compare 30 and 7 → swap → [25, 7, 30, 10, 45, 62]
3) Compare 30 and 10 → swap → [25, 7, 10, 30, 45, 62]
End of Pass 3: [25, 7, 10, 30, 45, 62]
Pass 4 (i = 4)
1) Compare 25 and 7 → swap → [7, 25, 10, 30, 45, 62]
2) Compare 25 and 10 → swap → [7, 10, 25, 30, 45, 62]
End of Pass 4: [7, 10, 25, 30, 45, 62]
Pass 5 (i = 5)
1) Compare 7 and 10 → no swap → [7, 10, 25, 30, 45, 62]
End of Pass 5: [7, 10, 25, 30, 45, 62]
Note: No swaps happened, so the list is already sorted (early stop).
Final Sorted List (Ascending): [7, 10, 25, 30, 45, 62]
Algorithm (Steps)
1) Start from the first element of the array.
2) Assume the first element is the minimum element.
3) Compare this minimum element with the remaining elements of the array.
4) If a smaller element is found, update the minimum element.
5) Swap the minimum element with the first element of the unsorted part.
6) Move the boundary of the sorted part one position forward.
7) Repeat the above steps until the entire array is sorted.
selectionSort(array)
for i ← 1 to sizeOfArray − 1
minIndex ← i
for j ← i + 1 to sizeOfArray
if array[j] < array[minIndex]
minIndex ← j
end for
if minIndex ≠ i
swap array[i] and array[minIndex]
end for
end selectionSort
Insertion Sort — Step-by-step Execution
Initial Array: [30, 25, 62, 45, 7, 10]
Pass 1 (i = 2, key = 25)
Compare 25 with 30 → shift 30 to the right
Insert 25 at position 1
Array after Pass 1: [25, 30, 62, 45, 7, 10]
Pass 2 (i = 3, key = 62)
Compare 62 with 30 → no shift required
Array after Pass 2: [25, 30, 62, 45, 7, 10]
Pass 3 (i = 4, key = 45)
Compare 45 with 62 → shift 62 to the right
Compare 45 with 30 → stop shifting
Insert 45 in correct position
Array after Pass 3: [25, 30, 45, 62, 7, 10]
Pass 4 (i = 5, key = 7)
Compare 7 with 62 → shift 62 to the right
Compare 7 with 45 → shift 45 to the right
Compare 7 with 30 → shift 30 to the right
Compare 7 with 25 → shift 25 to the right
Insert 7 at the beginning
Array after Pass 4: [7, 25, 30, 45, 62, 10]
Pass 5 (i = 6, key = 10)
Compare 10 with 62 → shift 62 to the right
Compare 10 with 45 → shift 45 to the right
Compare 10 with 30 → shift 30 to the right
Compare 10 with 25 → shift 25 to the right
Compare 10 with 7 → stop shifting
Insert 10 in correct position
Array after Pass 5: [7, 10, 25, 30, 45, 62]
Final Sorted Array (Ascending Order): [7, 10, 25, 30, 45, 62]
Algorithm (Steps)
1) Choose a pivot element from the array.
2) Rearrange the array so that elements smaller than the pivot are on the left and larger elements are on the right.
3) Place the pivot in its correct position.
4) Recursively apply Quick Sort on the left subarray.
5) Recursively apply Quick Sort on the right subarray.
6) Repeat the process until the entire array is sorted.
quickSort(array, low, high)
if low < high
pivotIndex ← partition(array, low, high)
quickSort(array, low, pivotIndex − 1)
quickSort(array, pivotIndex + 1, high)
end quickSort
partition(array, low, high)
pivot ← array[high]
i ← low − 1
for j ← low to high − 1
if array[j] < pivot
i ← i + 1
swap array[i] and array[j]
swap array[i + 1] and array[high]
return i + 1
Selection Sort — Step-by-step Example
Given Array: [30, 25, 62, 45, 7, 10]
Pass 1 (i = 1)
Assume minimum = 30
Compare 30 with 25 → new minimum = 25
Compare 25 with 62 → no change
Compare 25 with 45 → no change
Compare 25 with 7 → new minimum = 7
Compare 7 with 10 → no change
Swap 30 and 7
Array after Pass 1: [7, 25, 62, 45, 30, 10]
Pass 2 (i = 2)
Assume minimum = 25
Compare 25 with 62 → no change
Compare 25 with 45 → no change
Compare 25 with 30 → no change
Compare 25 with 10 → new minimum = 10
Swap 25 and 10
Array after Pass 2: [7, 10, 62, 45, 30, 25]
Pass 3 (i = 3)
Assume minimum = 62
Compare 62 with 45 → new minimum = 45
Compare 45 with 30 → new minimum = 30
Compare 30 with 25 → new minimum = 25
Swap 62 and 25
Array after Pass 3: [7, 10, 25, 45, 30, 62]
Pass 4 (i = 4)
Assume minimum = 45
Compare 45 with 30 → new minimum = 30
Compare 30 with 62 → no change
Swap 45 and 30
Array after Pass 4: [7, 10, 25, 30, 45, 62]
Pass 5 (i = 5)
Assume minimum = 45
Compare 45 with 62 → no change
No swap needed
Array after Pass 5: [7, 10, 25, 30, 45, 62]
Final Sorted Array (Ascending Order): [7, 10, 25, 30, 45, 62]
Algorithm (Steps)
1) Divide the given array into two halves.
2) Recursively apply Merge Sort on the left half.
3) Recursively apply Merge Sort on the right half.
4) Merge the two sorted halves into a single sorted array.
5) Repeat the process until the entire array is sorted.
mergeSort(array, left, right)
if left < right
mid ← (left + right) / 2
mergeSort(array, left, mid)
mergeSort(array, mid + 1, right)
merge(array, left, mid, right)
end mergeSort
merge(array, left, mid, right)
n1 ← mid − left + 1
n2 ← right − mid
create array L[1..n1] and R[1..n2]
for i ← 1 to n1
L[i] ← array[left + i − 1]
for j ← 1 to n2
R[j] ← array[mid + j]
i ← 1, j ← 1, k ← left
while i ≤ n1 and j ≤ n2
if L[i] ≤ R[j]
array[k] ← L[i]
i ← i + 1
else
array[k] ← R[j]
j ← j + 1
k ← k + 1
while i ≤ n1
array[k] ← L[i]
i ← i + 1
k ← k + 1
while j ≤ n2
array[k] ← R[j]
j ← j + 1
k ← k + 1
end merge
Merge Sort — Step-by-step Example (Ascending)
Given Array: [30, 25, 62, 45, 7, 10]
Step 1: Divide (Split) the array
Split into two halves:
Left = [30, 25, 62]
Right = [45, 7, 10]
Step 2: Divide the Left half
Left = [30, 25, 62] → Split into:
L1 = [30, 25]
L2 = [62]
Step 3: Divide L1 further
L1 = [30, 25] → Split into:
[30] and [25]
Step 4: Merge (Sort) [30] and [25]
Merge → [25, 30]
Step 5: Merge [25, 30] and [62]
Merge → [25, 30, 62]
Sorted Left Half: [25, 30, 62]
Step 6: Divide the Right half
Right = [45, 7, 10] → Split into:
R1 = [45, 7]
R2 = [10]
Step 7: Divide R1 further
R1 = [45, 7] → Split into:
[45] and [7]
Step 8: Merge (Sort) [45] and [7]
Merge → [7, 45]
Step 9: Merge [7, 45] and [10]
Merge → [7, 10, 45]
Sorted Right Half: [7, 10, 45]
Step 10: Final Merge of two sorted halves
Merge [25, 30, 62] and [7, 10, 45]:
Result → [7, 10, 25, 30, 45, 62]
Final Sorted Array (Ascending Order): [7, 10, 25, 30, 45, 62]
<
Algorithm (Steps)
1) Choose a pivot element from the array.
2) Rearrange the array so that elements smaller than the pivot are on the left and larger elements are on the right.
3) Place the pivot in its correct position.
4) Recursively apply Quick Sort on the left subarray.
5) Recursively apply Quick Sort on the right subarray.
6) Repeat the process until the entire array is sorted.
quickSort(array, low, high)
if low < high
pivotIndex ← partition(array, low, high)
quickSort(array, low, pivotIndex − 1)
quickSort(array, pivotIndex + 1, high)
end quickSort
partition(array, low, high)
pivot ← array[high]
i ← low − 1
for j ← low to high − 1
if array[j] < pivot
i ← i + 1
swap array[i] and array[j]
swap array[i + 1] and array[high]
return i + 1