- User Input = 50
- User Output = 40
- User Inquiries = 35
- User Files = 6
- External Interface = 4
Step 1:
As the complexity adjustment factor is average (given in the question), the scale is set to 3 for each factor.
F = 14 × 3 = 42
Step 2:
Calculate the Complexity Adjustment Factor (CAF) using the formula:
CAF = 0.65 + (0.01 × F)
Substitute F = 42:
CAF = 0.65 + (0.01 × 42) = 1.07
Step 3:
Calculate the Unadjusted Function Points (UFP) using the given values and the corresponding weights (average weighting factors):
UFP = (50 × 4) + (40 × 5) + (35 × 4) + (6 × 10) + (4 × 7)
UFP = 200 + 200 + 140 + 60 + 28 = 628
Step 4:
Calculate the Function Point (FP) using the formula:
FP = UFP × CAF
FP = 628 × 1.07 = 671.96
Final Answer:
The Function Point (FP) is: 671.96
Algorithm to Find the Smallest Element in an Array
START
Step 1 → Initialize an array A with given values.
Step 2 → Create a variable min_value and set it to a large number (e.g., infinity) or the first element of the array.
Step 3 → Loop through each element A[i] in the array starting from the first element.
Step 4 → For each element, check if A[i] is smaller than min_value.
Step 5 → If A[i] < min_value, update min_value to A[i].
Step 6 → Repeat Steps 4 and 5 until all elements have been checked.
Step 7 → Display min_value as the smallest element of the array.
STOP
Given:
- Page reference string: 1, 3, 0, 3, 5, 6, 3
- Number of page frames: 3
Step-by-Step Analysis:
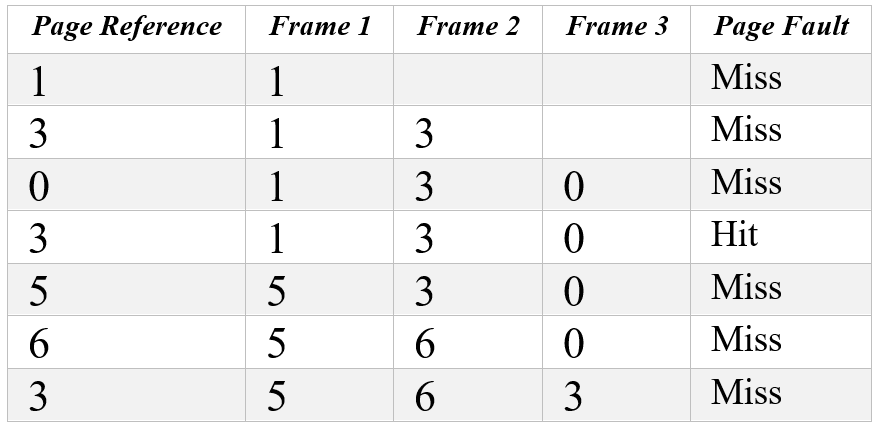
Explanation:
- 1 causes a page fault as it’s not in memory, so it’s loaded into frame 1.
- 3 causes a page fault and is loaded into frame 2.
- 0 causes a page fault and is loaded into frame 3. All three frames are now full.
- 3 is already in memory, so no page fault occurs (Hit).
- 5 causes a page fault and replaces the oldest page in memory, which is 1.
- 6 causes a page fault and replaces the oldest page in memory, which is 3.
- 3 causes a page fault and replaces the oldest page in memory, which is 0.
Total Page Faults:
- 6 Page Faults
Solution:
Step 1: Represent Data and Divisor in Polynomial Form
Data (11100):
x4 + x3 + x2
Divisor (1001):
x3 + 1
Step 2: Append Zeros to the Original Data
Since the divisor is 4 bits, we append 3 zeros to the original data (one less than the number of bits in the divisor). The new data is:
Data after appending zeros: 11100000
Step 3: Perform Binary Division
Now we divide the modified data 11100000 by the divisor 1001.
Division Process:
11111 ← Quotient
—————————–
11100000 ← Dividend (data with zeros)
1001 ← Divisor
———————-
1110000
1001
—————-
111000
1001
—————
11100
1001
————
1110
1001
————
111
Step 4: Determine the Transmitted Value
The remainder 111 is the CRC code. To get the transmitted value, append the remainder to the original data:
Original data: 11100
Remainder: 111
Transmitted Value: 11100111


