Bangladesh Bank • Year 2026
Bangladesh Bank
💼Post Name: Assistant Engineer (IT) / AME
📅Exam Date: 08-May-2026
- 1Data Center & VirtualizationRAIDA maintenance engineer is setting up a RAID 5 array with five hard drives, each having a capacity of 4 TB. What is the total usable storage capacity, and why is it not 20 TB?
- 2Data Center & VirtualizationMaintenanceDistinguish between Preventive and Corrective maintenance with a real-world example for each in a data center environment. A critical system consists of three components: Power Supply, Motherboard, and Storage, connected in a series configuration. If each component has a reliability of 0.95, what is the total reliability of the system?
- 3Computer NetworkOSI/TCP-IPAt which layer of the OSI model does a standard Router primarily operate, and what is the specific name of the Protocol Data Unit (PDU) at this layer? A router has four contiguous /24 routing table entries: 10.1.0.0/24, 10.1.1.0/24, 10.1.2.0/24, and 10.1.3.0/24. If you summarize these into a single route, what will be the new CIDR notation?
- 4Database Management SystemACIDWhat does the Consistency property in ACID guarantee during a bank fund transfer transaction? You are designing the schema for a Savings_Accounts table. Write the specific SQL constraint clause to ensure that the current_balance column can never drop below zero.
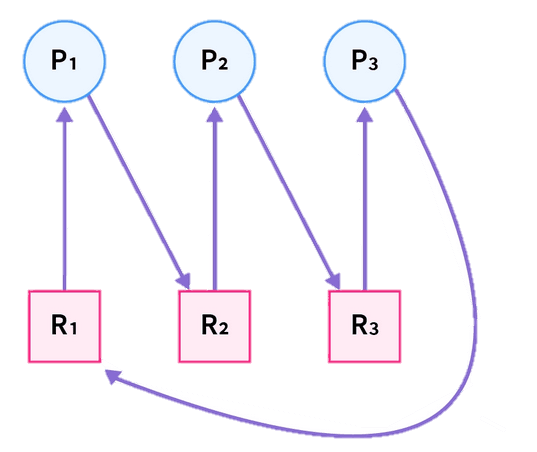
- 5Operating SystemDeadlockBriefly explain Circular Wait. In a Resource Allocation Graph (RAG), if a cycle exists, does it absolutely guarantee that a Deadlock has occurred? Explain briefly.
Circular Wait
- Circular wait is one of the necessary conditions for deadlock.
- It occurs when a group of processes are waiting for resources in a circular chain.
- In this situation, each process holds at least one resource and waits for another resource held by the next process in the cycle.
Example:
- Process P1 holds Resource R1 and waits for R2.
- Process P2 holds Resource R2 and waits for R3.
- Process P3 holds Resource R3 and waits for R1.
This creates a circular waiting condition.

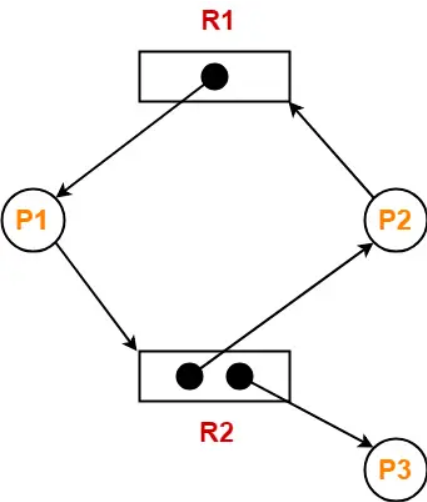
Cycle in Resource Allocation Graph (RAG)
If a cycle exists in a Resource Allocation Graph, it does not always guarantee deadlock.
- If each resource type has only one instance, then a cycle definitely indicates deadlock.
- If resource types have multiple instances, then a cycle may exist without deadlock.
So, a cycle is:
- A necessary condition for deadlock
- But not always a sufficient condition
Deadlock Detection using Resource Allocation Graph
To detect deadlock using Resource Allocation Graph (RAG), we follow these steps −
- If RAG contains no cycles, then there is no deadlock in the system.
- If RAG is of single instance resources and it contains a cycle, then there is a deadlock in the system.
- If RAG is of multiple instance resources and it contains a cycle, then deadlock may or may not exist. To check for deadlock, we need convert multiple instance RAG to single instance RAG, by treating each instance of a resource as a separate resource type.

In the graph:
- Resource R1 has only one instance.
- Resource R2 has two instances.
- P1 is holding R1 and requesting R2.
- P2 is holding one instance of R2 and requesting R1.
- P3 is using another instance of R2.
A cycle exists in the graph: P1 → R2 → P2 → R1 → P1
But this graph does not indicate deadlock.
Reason:
Resource R2 has multiple instances. One instance of R2 is currently allocated to P3.
If P3 finishes its work and releases R2, then:
- P1 can obtain R2 and complete execution.
- After P1 completes, it releases R1.
- Then P2 can obtain R1 and continue execution.
Since the processes can still proceed and resources can eventually be released, the system is not permanently blocked.
- 6Computer SecurityOthersA server suddenly starts sending abnormal traffic to external systems. Analyze the possible cause and suggest immediate actions.
- 7Big Data, ML & AIHadoop EcosystemA financial services provider needs to handle massive streaming and historical log data to perform fraud analytics and ML-driven maintenance prediction. Identify five Hadoop ecosystem technologies appropriate for this use case and describe their roles.
- 8Web TechnologyHTTPExplain HTTP status codes.
- 9Computer SecurityDifferent AttacksDefine zero-day attacks. Compare the technologies used to secure data in transit versus data at rest.
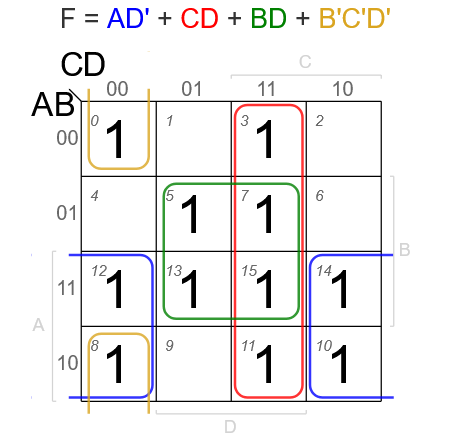
- 10Digital Logic DesignSimplify the Boolean equation using K-map: F(A,B,C,D) = Σ(0,3,5,7,8,10,11,12,13,14,15).

2 thoughts on “Bangladesh Bank, AME/AE (IT), 2026”
Some Questions are missing
অনলাইনে এগুলাই পেলাম ভাই।