Question Bank(2021-2026)-AME/AE/ANE
Question Bank(2021-2026)- Senior Officer (IT)
Combined Bank, Senior Officer (IT), 2025 (exam date: 17-10-2025)
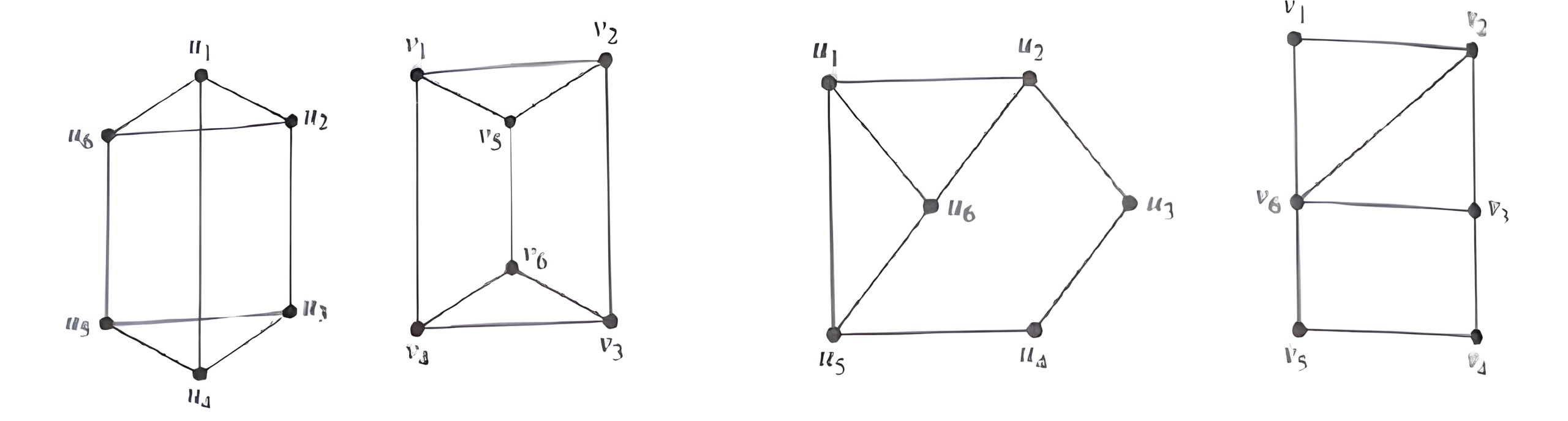 (10 Marks)
(10 Marks)a. How many bits are required in the logical address?
b. How many bits are required in the physical address? (10 Marks)
#include <stdio.h> /* Function to calculate sum of even numbers from 1 to n */ int sumOfEven(int n) { int sum = 0; for (int i = 2; i <= n; i += 2) { sum += i; } return sum; } int main() { int n, result; printf("Enter an integer: "); scanf("%d", &n); result = sumOfEven(n); printf("Sum of even numbers from 1 to %d = %d\n", n, result); return 0; }
Sample I/O:
Enter an integer: 50
Sum of even numbers from 1 to 50 = 650
=== Code Execution Successful ===
Combined Bank, Senior Officer (IT), 2024 (exam date: 17-05-2024)
A microcontroller is a small, low-cost microcomputer designed to perform specific tasks in embedded systems. It integrates a processor, memory (RAM, ROM, EPROM), and peripherals such as timers, counters, and serial ports into a single chip. Microcontrollers are commonly used in applications like microwave ovens, remote controls, and IoT devices.
Difference Between Microprocessor and Microcontroller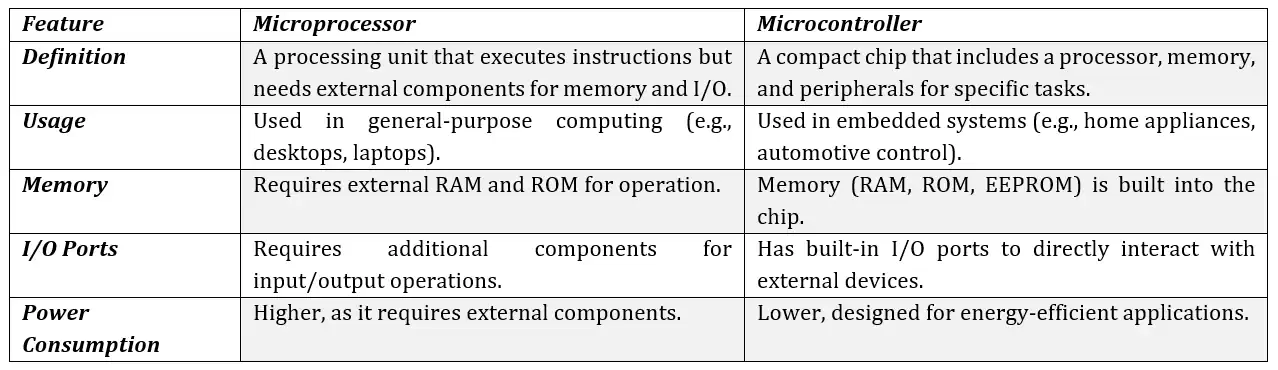
Differences Between RISC and CISC Microprocessors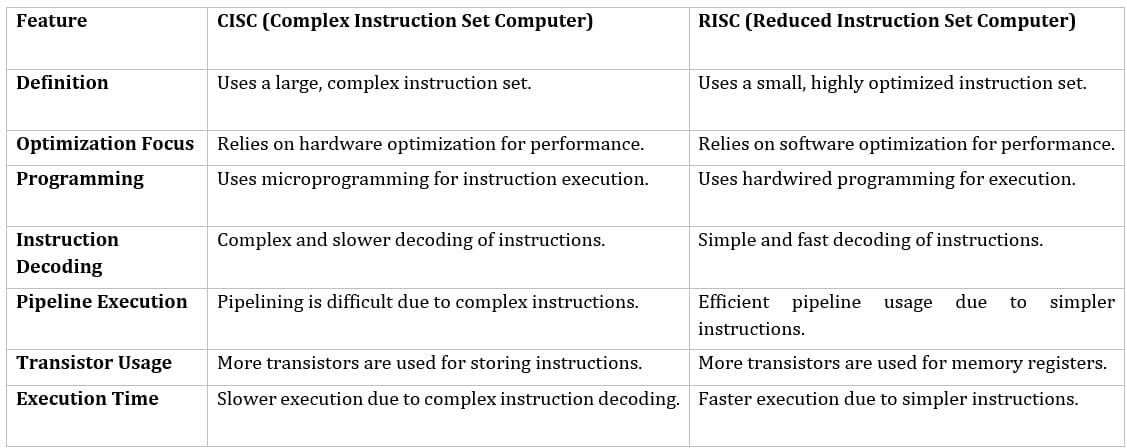
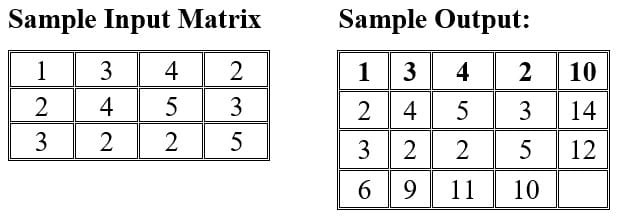
✅ C Program to Compute Row and Column Sum of a Matrix
#include <stdio.h>
int main() {
int m, n, i, j;
// Input matrix dimensions
printf("Enter the number of rows (m): ");
scanf("%d", &m);
printf("Enter the number of columns (n): ");
scanf("%d", &n);
int matrix[m][n];
// Input matrix elements
printf("Enter the elements of the matrix row-wise:\n");
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++) {
scanf("%d", &matrix[i][j]);
}
}
// Calculate and print row sums
printf("\nMatrix with Row Sums:\n");
for (i = 0; i < m; i++) {
int rowSum = 0;
for (j = 0; j < n; j++) {
printf("%d ", matrix[i][j]);
rowSum += matrix[i][j];
}
printf("%d\n", rowSum); // Row sum
}
// Calculate and print column sums
printf("\nColumn Sums:\n");
for (j = 0; j < n; j++) {
int colSum = 0;
for (i = 0; i < m; i++) {
colSum += matrix[i][j];
}
printf("%d ", colSum);
}
return 0;
}
Sample I/O:Enter the number of rows (m): 3
Enter the number of columns (n): 4
Enter the elements of the matrix row-wise:
1 3 4 2
2 4 5 3
3 2 2 5
Output:
Matrix with Row Sums:
1 3 4 2 10
2 4 5 3 14
3 2 2 5 12
Column Sums:
6 9 11 10
Sample input:
Enter value of n: 20
Sample Output:
Prime Numbers: 2, 3, 5, 7, 11, 13, 17, 19
#include <iostream>
using namespace std;
bool isPrime(int num) {
if (num < 2) return false;
for (int i = 2; i * i <= num; i++) {
if (num % i == 0) return false;
}
return true;
}
void findPrimes(int n) {
cout << "Prime Numbers: ";
for (int i = 1; i <= n; i++) {
if (isPrime(i))
cout << i << " ";
}
cout << endl;
}
int main() {
int n;
cout << "Enter value of n: ";
cin >> n;
findPrimes(n);
return 0;
}
Sample I/O:Enter value of n: 20
Prime Numbers: 2 3 5 7 11 13 17 19
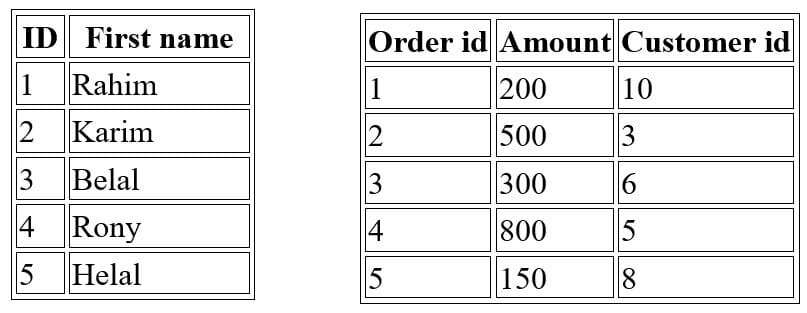
SELECT Customers.ID, Customers.FirstName, Orders.OrderID, Orders.Amount FROM Customers INNER JOIN Orders ON Customers.ID = Orders.CustomerID;Result Set:
| ID | First Name | Order ID | Amount |
|---|---|---|---|
| 3 | Belal | 2 | 500 |
| 5 | Helal | 4 | 800 |
Left Join (or Left Outer Join):A Left Join returns all rows from the left table (Customers), and the matched rows from the right table (Orders). If there is no match, the result is NULL on the right side.
SELECT Customers.ID, Customers.FirstName, Orders.OrderID, Orders.Amount FROM Customers LEFT JOIN Orders ON Customers.ID = Orders.CustomerID;Result Set:
| ID | First Name | Order ID | Amount |
|---|---|---|---|
| 1 | Rahim | NULL | NULL |
| 2 | Karim | NULL | NULL |
| 3 | Belal | 2 | 500 |
| 4 | Rony | NULL | NULL |
| 5 | Helal | 4 | 800 |
Right Join (or Right Outer Join):A Right Join returns all rows from the right table (Orders), and the matched rows from the left table (Customers). If there is no match, the result is NULL on the left side.
SELECT Customers.ID, Customers.FirstName, Orders.OrderID, Orders.Amount FROM Customers RIGHT JOIN Orders ON Customers.ID = Orders.CustomerID;Result Set:
| ID | First Name | Order ID | Amount |
|---|---|---|---|
| NULL | NULL | 1 | 200 |
| 3 | Belal | 2 | 500 |
| NULL | NULL | 3 | 300 |
| 5 | Helal | 4 | 800 |
| NULL | NULL | 5 | 150 |
Full Join (or Full Outer Join):A Full Join returns all rows when there is a match in either the left (Customers) or right (Orders) table. Rows without a match in one of the tables will have NULLs in the corresponding columns.
SELECT Customers.ID, Customers.FirstName, Orders.OrderID, Orders.Amount FROM Customers FULL OUTER JOIN Orders ON Customers.ID = Orders.CustomerID;Result Set:
| ID | First Name | Order ID | Amount |
|---|---|---|---|
| 1 | Rahim | NULL | NULL |
| 2 | Karim | NULL | NULL |
| 3 | Belal | 2 | 500 |
| 4 | Rony | NULL | NULL |
| 5 | Helal | 4 | 800 |
| NULL | NULL | 1 | 200 |
| NULL | NULL | 3 | 300 |
| NULL | NULL | 5 | 150 |
Primary Key, Foreign Key, and Indexing in Relational Databases
Primary Key: A primary key is a column (or a set of columns) that uniquely identifies each row in a table.
Example: Student Table
| Stu_Id | Stu_Name | Stu_Age |
|---|---|---|
| 101 | Steve | 23 |
| 102 | John | 24 |
| 103 | Robert | 28 |
| 104 | Steve | 29 |
- Stu_Id can be the primary key because it is unique for each student.
- Stu_Name alone cannot be a primary key, as multiple students can have the same name.
- Stu_Age alone cannot be a primary key, as multiple students can have the same age.
Foreign Key: A foreign key is a column in one table that references the primary key of another table. It establishes relationships between tables.
Example: Course Enrollment Table
| Course_Id | Stu_Id |
|---|---|
| C01 | 101 |
| C02 | 102 |
| C03 | 101 |
- In this table, Stu_Id is a foreign key as it references the primary key (Stu_Id) from the Student table.
Indexing: Indexing improves the speed of data retrieval in a database.
- Advantages: Indexing speeds up search queries, improves performance, and reduces load time.
- Disadvantages: Indexes require extra storage and may slow down insert, update, and delete operations.
Does Indexing Always Make Applications Faster?
- Yes, for read-heavy databases where fast searches are needed.
- No, for write-heavy databases where frequent inserts and updates happen, as indexing can slow them down.
Data transmission mode is a process by which data is sent from a source to one or more destinations. Simply put, it defines how data flows from one device to another. It is also known as Communication Mode.
Types of Data Transmission Modes
1. Simplex Mode
– Communication is one-way only.
– Data flows in a single direction, meaning one device can only send data while the other can only receive it.
– No two-way communication.
Example: Keyboard to Computer, Radio, Television.
[Source] ----> [Destination]
2. Half-Duplex Mode
– Data can flow in both directions, but only one direction at a time.
– The entire communication channel is used for sending data in one direction at a time.
– Error detection is possible.
Example: Walkie-Talkie Communication.
[Source] ----> [Destination] [Source] <---- [Destination]
3. Full-Duplex Mode
– Data flows in both directions simultaneously.
– Both devices can send and receive data at the same time.
– Uses two simplex channels, where one channel sends data in one direction, and the other channel sends data in the opposite direction.
Example: Mobile Phones, Telephones.
[Source] <----> [Destination]

To develop and deploy the software system as quickly as possible, I would choose the Incremental Approach over the Waterfall Approach. Here’s why:
Faster Delivery & Early Value:
- Incremental Approach: Delivers software in smaller, working parts, allowing early use and feedback.
- Waterfall Approach: Requires full completion of all phases before any part is usable, leading to long waiting times.
Flexibility & Adaptability:
- Incremental Approach: Allows changes and improvements throughout development.
- Waterfall Approach: Changes are difficult and costly once requirements are set.
Risk Management:
- Incremental Approach: Issues are detected and fixed early, reducing risks.
- Waterfall Approach: Risks are identified late, leading to costly rework.
User Feedback:
- Incremental Approach: Users can give feedback during development to refine the system.
- Waterfall Approach: Feedback comes only after full development, risking mismatches with user needs.
Resource Allocation:
- Incremental Approach: Resources are managed efficiently, focusing on smaller increments.
- Waterfall Approach: All resources are tied up until full system completion.
Combined Bank, Senior Officer (IT), 2023 (exam date: 13-10-2023)
 Relation between Data, Segment, Packet and Bit in OSI ModelAs data moves down through the OSI layers, it changes its form. This process is called encapsulation.
Relation between Data, Segment, Packet and Bit in OSI ModelAs data moves down through the OSI layers, it changes its form. This process is called encapsulation.- Data: At the Application, Presentation, and Session layers, information is called Data.
- Segment: At the Transport layer, data is divided into Segments (TCP) or Datagrams (UDP).
- Packet: At the Network layer, segments are encapsulated into Packets.
- Frame: At the Data Link layer, packets are converted into Frames.
- Bit: At the Physical layer, frames are transmitted as Bits (0s and 1s).
 OSI Model-এ Data, Segment, Packet ও Bit-এর সম্পর্কOSI Model-এর বিভিন্ন layer দিয়ে data যাওয়ার সময় তার রূপ পরিবর্তন হয়, একে Encapsulation বলা হয়।
OSI Model-এ Data, Segment, Packet ও Bit-এর সম্পর্কOSI Model-এর বিভিন্ন layer দিয়ে data যাওয়ার সময় তার রূপ পরিবর্তন হয়, একে Encapsulation বলা হয়।- Data: Application, Presentation ও Session layer-এ তথ্যকে Data বলা হয়।
- Segment: Transport layer-এ data ভাগ হয়ে Segment হয়।
- Packet: Network layer-এ Segment থেকে Packet তৈরি হয়।
- Frame: Data Link layer-এ Packet থেকে Frame হয়।
- Bit: Physical layer-এ Frame bit (0 ও 1) আকারে পাঠানো হয়।
Network Topology
Network topology refers to the physical or logical arrangement of computers, devices, and communication links in a network that determines how data is transmitted.
Example: Computers connected through a central switch in an office network follow Star topology.
1. Bus Topology
Working: In bus topology, all devices are connected to a single backbone cable. When a device sends data, it travels along the cable and reaches all devices, but only the intended receiver accepts it.
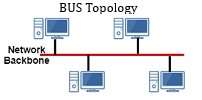
Advantage: Low installation cost and simple structure.
2. Ring Topology
Working: In ring topology, devices are connected in a circular manner. Data moves in one direction from one device to the next until it reaches the destination.
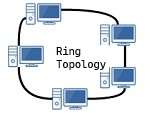
Advantage: No data collision occurs.
3. Star Topology
Working: In star topology, all devices are connected to a central hub or switch. Data sent by a device first goes to the hub, which then forwards it to the destination device.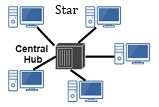
Advantage: Easy to manage and troubleshoot.
4. Tree Topology
Working: Tree topology uses a hierarchical structure where multiple star networks are connected to a main backbone cable, and data flows from parent nodes to child nodes.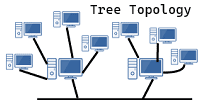
Advantage: Suitable for large and expandable networks.
3. Purpose of IEEE 802.11 Committee
The IEEE 802.11 committee is responsible for developing standards for
Wireless Local Area Networks (WLAN).
- Defines Wi-Fi communication standards
- Ensures interoperability between wireless devices
- Improves wireless speed, security, and reliability
Network Topology
Network Topology বলতে একটি network-এ computer, device এবং communication link-এর physical বা logical বিন্যাসকে বোঝায়, যা data চলাচলের পদ্ধতি নির্ধারণ করে।
উদাহরণ: একটি office network-এ central switch ব্যবহার করে computer সংযোগ করা Star topology-এর উদাহরণ।
১. Bus Topology
কাজ: Bus topology-তে সব ডিভাইস একটি backbone cable-এর সাথে যুক্ত থাকে। কোনো ডিভাইস data পাঠালে তা cable দিয়ে সব ডিভাইসে পৌঁছায়, কিন্তু নির্দিষ্ট receiver-ই data গ্রহণ করে।
সুবিধা: গঠন সহজ এবং খরচ কম।
২. Ring Topology
কাজ: Ring topology-তে ডিভাইসগুলো বৃত্তাকারে সংযুক্ত থাকে। Data একদিকে ঘুরে এক ডিভাইস থেকে অন্য ডিভাইসে যায় যতক্ষণ না গন্তব্যে পৌঁছায়।
সুবিধা: Data collision হয় না।
৩. Star Topology
কাজ: Star topology-তে সব ডিভাইস একটি central hub বা switch-এর সাথে যুক্ত থাকে। Data প্রথমে hub-এ যায়, তারপর destination ডিভাইসে পাঠানো হয়।
সুবিধা: Management ও troubleshooting সহজ।
৪. Tree Topology
কাজ: Tree topology-তে hierarchical কাঠামো ব্যবহার করা হয়, যেখানে একাধিক star network একটি main backbone-এর সাথে যুক্ত থাকে এবং data parent node থেকে child node-এ প্রবাহিত হয়।
সুবিধা: বড় ও expandable network-এর জন্য উপযোগী।
৩. IEEE 802.11 Committee-এর উদ্দেশ্য
IEEE 802.11 Committee-এর প্রধান উদ্দেশ্য হলো
Wireless Local Area Network (WLAN)-এর জন্য
standard তৈরি ও উন্নয়ন করা।
- Wi-Fi standard নির্ধারণ করা
- Wireless device-এর compatibility নিশ্চিত করা
- Wireless network-এর speed ও security বৃদ্ধি করা
Diagram for e-commerce online transactions.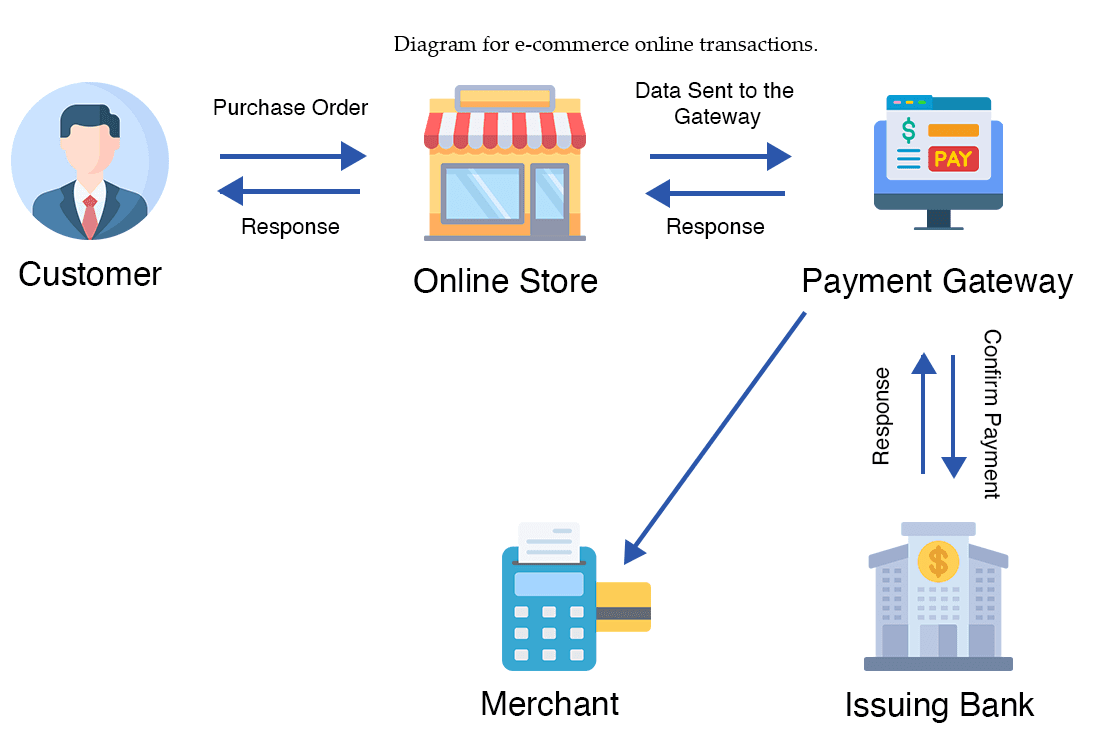
A) Find matrices C that is multiplication A and B.
B) Find average in A and B.
C) Max from matrices C 10
#include <iostream>
using namespace std;
void matrix_multiply(int A[10][10], int B[10][10], int C[10][10], int m, int n, int p, int q) {
if (n != p) {
cout << "Matrices A and B cannot be multiplied due to incompatible dimensions.\n";
return;
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < q; j++) {
C[i][j] = 0;
for (int k = 0; k < n; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
float calculate_average(int matrix[10][10], int m, int n) {
int sum = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
sum += matrix[i][j];
}
}
return static_cast(sum) / (m * n);
}
int find_max(int matrix[10][10], int m, int n) {
int max = matrix[0][0];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) { if (matrix[i][j] > max) {
max = matrix[i][j];
}
}
}
return max;
}
int main() {
int A[10][10], B[10][10], C[10][10];
int m, n, p, q;
cout << "Enter the number of rows and columns for matrix A (m x n): "; cin >> m >> n;
cout << "Enter the number of rows and columns for matrix B (p x q): "; cin >> p >> q;
if (n != p) {
cout << "Matrices A and B cannot be multiplied due to incompatible dimensions.\n";
return 0;
}
// Input matrices A and B
cout << "Enter elements of matrix A:\n";
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) { cin >> A[i][j];
}
}
cout << "Enter elements of matrix B:\n";
for (int i = 0; i < p; i++) {
for (int j = 0; j < q; j++) { cin >> B[i][j];
}
}
// A) Multiply matrices A and B
matrix_multiply(A, B, C, m, n, p, q);
cout << "Matrix C (A x B):\n";
for (int i = 0; i < m; i++) {
for (int j = 0; j < q; j++) {
cout << C[i][j] << " ";
}
cout << endl;
}
// B) Calculate the average of matrices A and B
float average_A = calculate_average(A, m, n);
float average_B = calculate_average(B, p, q);
cout << "Average of Matrix A: " << average_A << endl;
cout << "Average of Matrix B: " << average_B << endl;
// C) Find the maximum value in matrix C
int max_C = find_max(C, m, q);
cout << "Maximum value in Matrix C: " << max_C << endl;
return 0;
}
Sample I/O:
Enter the number of rows and columns for matrix A (m x n): 3 3
Enter the number of rows and columns for matrix B (p x q): 3 3
Enter elements of matrix A:
1 5 7 6 3 2 69 7 12
Enter elements of matrix B:
45 63 2 9 8 7 12 10 3
Matrix C (A x B):
174 173 58
321 422 39
3312 4523 223
Average of Matrix A: 12.4444
Average of Matrix B: 17.6667
Maximum value in Matrix C: 4523
=== Code Execution Successful ===
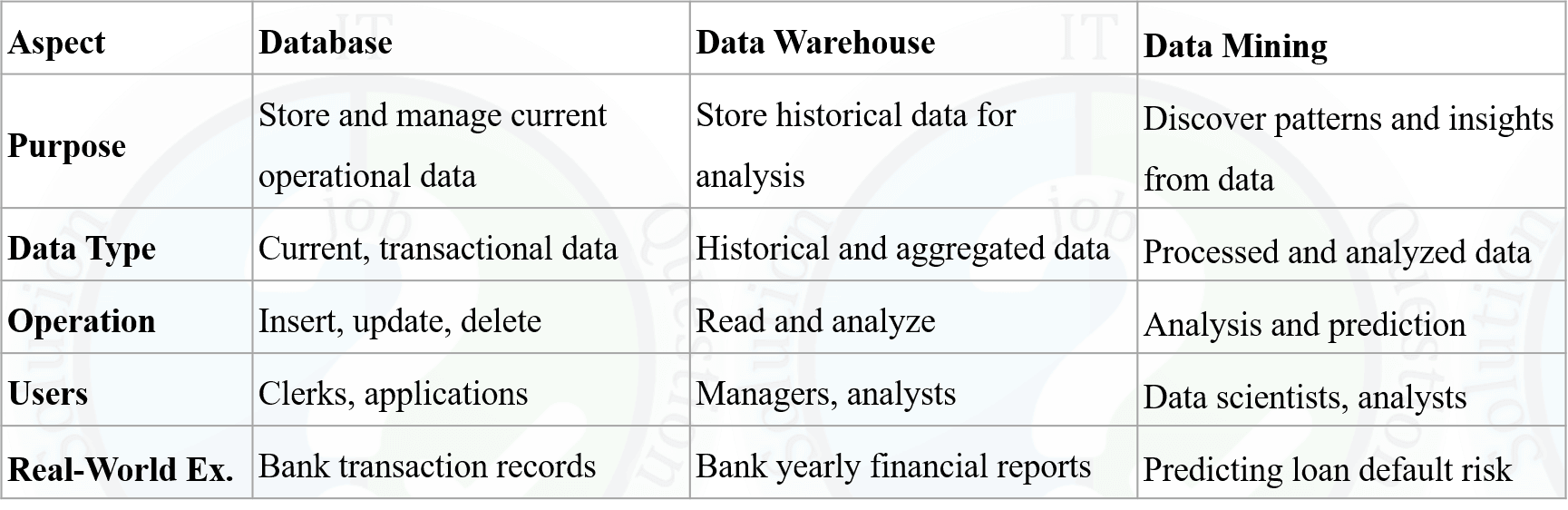
Database, Data Warehouse এবং Data Mining-এর পার্থক্য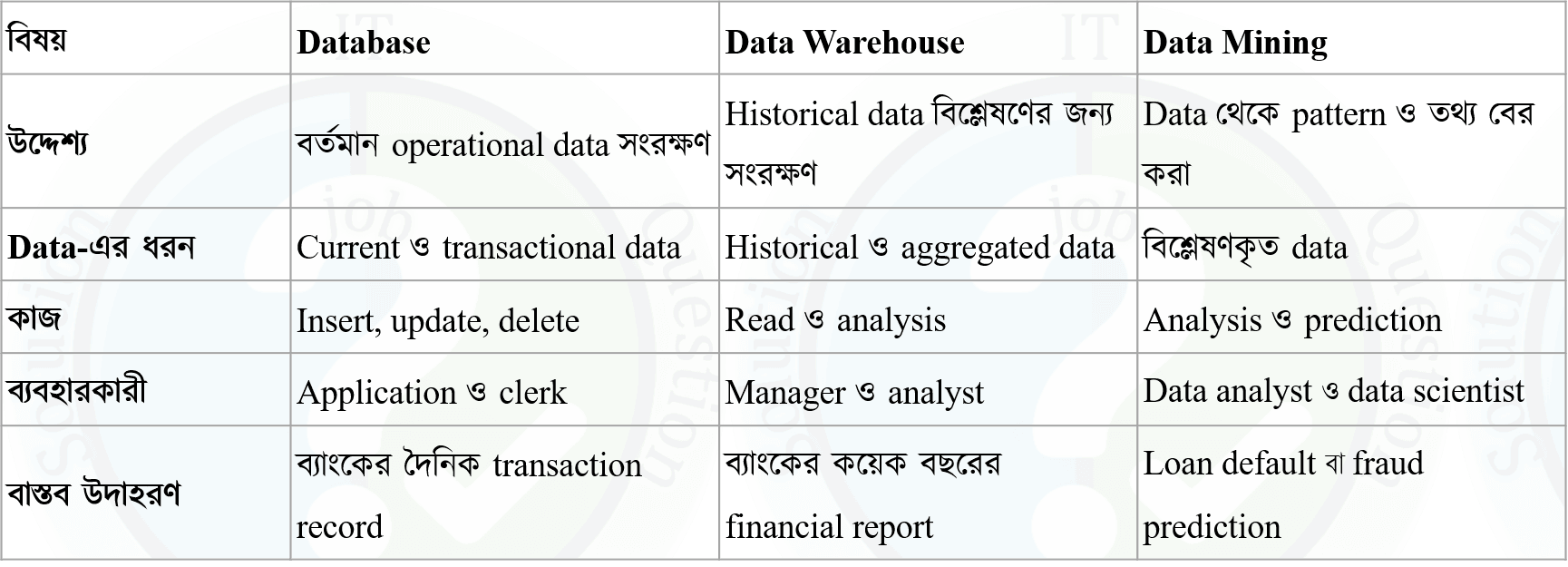
Combined Bank, Senior Officer (IT), 2022 (exam date: 31-01-2022)
CREATE TABLE:
A table t is created with one column val of type INTEGER.
INSERT INTO:
The values 1, 2, 2, 3, NULL, NULL, 4, 5 are inserted into the column val.
SELECT COUNT(val):
This query counts all non-NULL values in the val column.
Total non-NULL values: 1, 2, 2, 3, 4, 5
Result: 6
SELECT COUNT(DISTINCT val):
This query counts only the unique non-NULL values in the val column.
Unique values: 1, 2, 3, 4, 5
Result: 5
Note: Question Collect করা সম্ভব হয়নি।
i. Subnet Mask
ii. Block Size.
iii. Network Address
iv. Broadcast Address
v. Total valid Host.
Subnet Mask:/22 corresponds to the subnet mask 255.255.252.0.
Block Size: 2^(32−22)=2^10=1024.
Network Address: 172.16.16.0/22.
Broadcast Address: 172.16.19.255/22.
Total Valid Hosts: 2^(32−22)−2=1024−2=1022
Explanation
Given IP Address: 172.16.16.137/22
Step 1: /22 বোঝা
/22 মানে Network bits = 22
Host bits = 32 − 22 = 10 bits
Step 2: Subnet Mask লেখা
/22 এর Binary Subnet Mask:
11111111.11111111.11111100.00000000
Decimal Subnet Mask = 255.255.252.0
Step 3: IP Address কে Binary তে রূপান্তর
172 = 10101100
16 = 00010000
16 = 00010000
137 = 10001001
IP (Binary):
10101100.00010000.00010000.10001001
Step 4: AND Operation (Network Address)
IP Address AND Subnet Mask করা হয়।
যেখানে Subnet Mask = 0 → Host bits 0 হয়ে যায়।
IP: 10101100.00010000.00010000.10001001 Mask: 11111111.11111111.11111100.00000000 ------------------------------------------------ Result: 10101100.00010000.00010000.00000000
Binary Result কে Decimal এ রূপান্তর করলে:
Network Address = 172.16.16.0
Step 5: Broadcast Address বের করা
Broadcast address পেতে সব Host bits = 1 করা হয়।
Network (Binary): 10101100.00010000.00010000.00000000 Host bits (10 bits) = 1111111111 Broadcast (Binary): 10101100.00010000.00010011.11111111
Binary থেকে Decimal করলে:
Broadcast Address = 172.16.19.255
Step 6: Valid Host Range
First Host = Network + 1 → 172.16.16.1
Last Host = Broadcast − 1 → 172.16.19.254
Step 7: Total Valid Hosts
Host bits = 10
Total = 210 = 1024
Valid Hosts = 1024 − 2 = 1022
#include<stdio.h>
using namespace std;
// Recursive function to check if a string is a palindrome
bool isPalindrome(string str, int start, int end) {
// Base case: If the start index is greater than or equal to the end index
if (start >= end) {
return true;
}
// Check if the first and last characters are the same
if (str[start] != str[end]) {
return false;
}
// Recursive case: Check the substring excluding the first and last characters
return isPalindrome(str, start + 1, end - 1);
}
int main() {
string input;
cout << "Enter a string: "; cin >> input;
if (isPalindrome(input, 0, input.length() - 1)) {
cout << input << " is a palindrome." << endl;
} else {
cout << input << " is not a palindrome." << endl;
}
return 0;
}
Sample I/O:
Enter a string: noon
noon is a palindrome.
=== Code Execution Successful ===
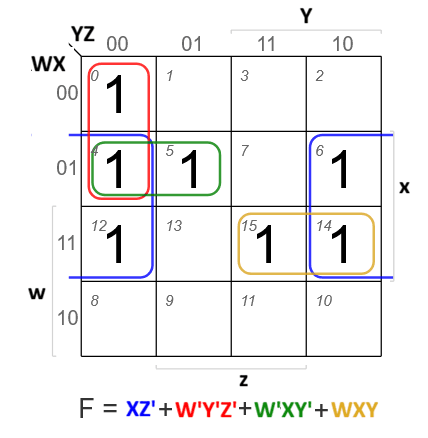
Capacity of a Track
Bytes per Track = Bytes per Sector × Sectors per Track
Bytes per Track = 512 × 50 = 25,600 bytes
Capacity of a Surface
Bytes per Surface = Bytes per Track × Tracks per Surface
Bytes per Surface = 25,600 × 2000 = 51,200,000 bytes (50,000 KB)
Capacity of the Disk
Bytes per Disk = Bytes per Surface × Number of Surfaces
Number of Surfaces = 5 Platters × 2 Surfaces per Platter = 10 Surfaces
Bytes per Disk = 51,200,000 × 10 = 512,000,000 bytes (500,000 KB)
C = B log2(1 + SNR)
= 3000 log2(1 + 3162)
= 3000 log2(3163)
= 3000 × 11.62
= 34,860 bps
Slow_solution(n){
result = 0;
for i in to (n){
for j in to (i+ 1){
result +=1;)
return result;}
Pre-order: a, b, e, j, k, n, o, p ,f, c, d, g ,l, m ,h,i;
Post-order:j, n, l, p, o, k, e, f, b, c, g, m, h, i, d, a;
a
/ \
b d
/ \ / \
e f g i
/ \ / \
j k l m
/ \
n o
\
p
Question Bank(2021-2026)-Assistant Programmer
Combined Bank, Assistant Programmer, 2026 (exam date: 17-01-2026)
Universal Gate
A Universal Gate is a logic gate that can be used to implement any Boolean function (i.e., any logic circuit). If we can build the basic gates NOT, AND, and OR using only one type of gate, then that gate is called a universal gate.
Proof: NAND is a Universal Gate
To prove NAND is universal, we show that we can construct NOT, AND, and OR using only NAND gates.
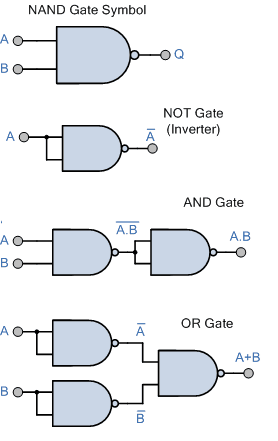
Since we can build NOT, AND, and OR using only NAND gates, we can build any Boolean expression. Therefore, the NAND gate is a Universal Gate.
Universal Gate
Universal Gate হলো এমন একটি logic gate যার সাহায্যে যেকোনো Boolean function বা যেকোনো logic circuit তৈরি করা যায়। যদি একটি মাত্র gate ব্যবহার করে NOT, AND, এবং OR gate তৈরি করা যায়, তাহলে সেই gate কে universal gate বলা হয়।
প্রমাণ: NAND Gate Universal Gate
NAND universal প্রমাণ করতে হলে দেখাতে হবে যে শুধুমাত্র NAND gate দিয়ে NOT, AND, এবং OR তৈরি করা যায়।
কারণ শুধুমাত্র NAND gate ব্যবহার করে NOT, AND, এবং OR তৈরি করা যায়, তাই যেকোনো Boolean function তৈরি করা সম্ভব। সুতরাং NAND gate একটি Universal Gate।
Combined Bank, Assistant Programmer, 2024 (exam date: 09-02-2024)
In Database Management Systems (DBMS), relationships define how data in different tables are connected.
There are three main types of relationships in a relational database:
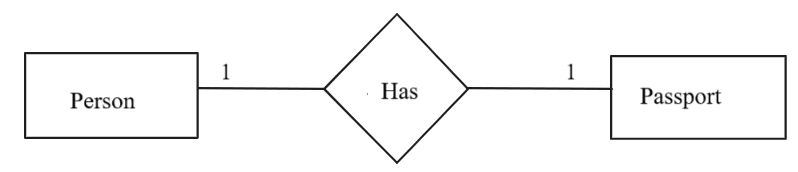
1. One-to-One (1:1) Relationship:
Each record in Table A is linked to only one record in Table B, and vice versa.
Example:
- A person and their passport (One person has only one passport, and one passport belongs to one person).
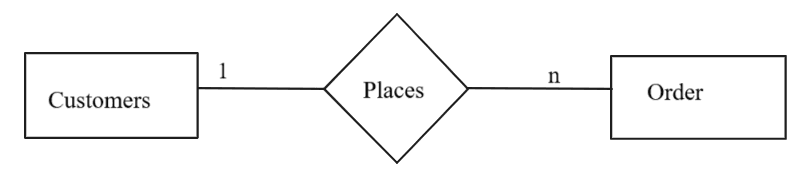
2. One-to-Many (1:M) Relationship:
A record in Table A can be linked to multiple records in Table B, but each record in Table B is linked to only one record in Table A.
Example:
- A customer can place multiple orders, but each order belongs to only one customer.
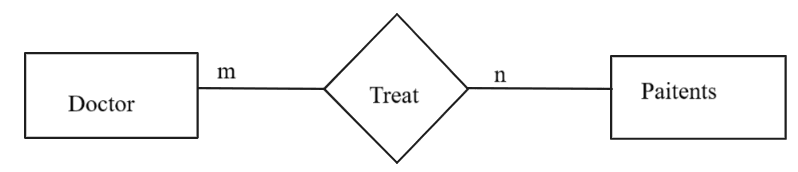
3. Many-to-Many (M:N) Relationship:
Each record in Table A can be linked to multiple records in Table B, and vice versa.
Example:
- A doctor can treat multiple patients, and a patient can have multiple doctors.
Database Management System (DBMS)-এ relationship ব্যবহার করা হয় বিভিন্ন table-এর মধ্যে
data কীভাবে একে অপরের সাথে সংযুক্ত তা বোঝানোর জন্য। Relational database-এ প্রধানত তিন ধরনের relationship রয়েছে:
১. One-to-One (1:1) Relationship:
এই relationship-এ Table A-এর একটি record শুধুমাত্র Table B-এর একটি record-এর সাথে যুক্ত থাকে,
এবং Table B-এর একটি record-ও শুধুমাত্র Table A-এর একটি record-এর সাথে যুক্ত থাকে।
উদাহরণ:
- একজন ব্যক্তি এবং তার passport (একজন ব্যক্তির একটি passport থাকে এবং একটি passport শুধুমাত্র একজন ব্যক্তিরই হয়)।
২. One-to-Many (1:M) Relationship:
এই relationship-এ Table A-এর একটি record Table B-এর একাধিক record-এর সাথে যুক্ত হতে পারে,
কিন্তু Table B-এর প্রতিটি record শুধুমাত্র Table A-এর একটি record-এর সাথেই যুক্ত থাকে।
উদাহরণ:
- একজন customer একাধিক order দিতে পারে, কিন্তু প্রতিটি order শুধুমাত্র একটি customer-এরই হয়।
৩. Many-to-Many (M:N) Relationship:
এই relationship-এ Table A-এর একটি record Table B-এর একাধিক record-এর সাথে যুক্ত হতে পারে,
এবং Table B-এর একটি record-ও Table A-এর একাধিক record-এর সাথে যুক্ত থাকতে পারে।
উদাহরণ:
- একজন doctor একাধিক patient-এর চিকিৎসা করতে পারে, এবং একজন patient একাধিক doctor-এর চিকিৎসা নিতে পারে।
Problems Solved by Stack:
1)Balancing Parentheses (Expression Validation)
2)Backtracking (Undo Operation)
Problems Solved by Queue:
1)Task Scheduling (CPU Scheduling)
2)BFS (Breadth-First Search) in Graphs
#include <stdio.h>
void fun(int x){
if(x<0){
return;
}
printf("%d\n", x--);
fun(--x);
printf("%d\n", x);
}
int main() {
fun(5);
return 0;
}
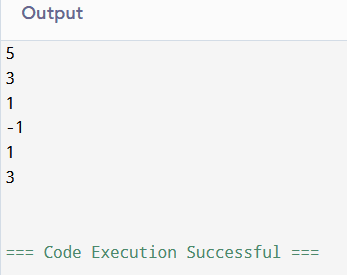
Step-by-Step Execution
Initial call:
fun(5)x = 5- Print
5 x--(post-decrement) → Passx = 4tofun(--x)
Recursive call:
fun(3)x = 3- Print
3 x--(post-decrement) → Passx = 2tofun(--x)
Recursive call:
fun(1)x = 1- Print
1 x--(post-decrement) → Passx = 0tofun(--x)
Recursive call:
fun(-1)x = -1- The
if(x<0) return;triggers, stopping recursion. - Nothing is printed here.
Returning from
fun(1):x = -1at this point (becausexwas decremented before recursion)- Print
-1
Returning from
fun(3):x = 1- Print
1
Returning from
fun(5):x = 3- Print
3
Bangladesh Bank, Assistant Programmer, 2023 (exam date: 03-02-2023)
The hash function is given as h(k)=k mod 13.
The table size is 13, meaning we have indices from 0 to 12.
Step-by-Step Insertion Process
Key: 10
Hash value: h(10) = 10 mod 13 = 10. Insert 10 at index 10.
Key: 3
Hash value: h(3) = 3 mod 13 = 3. Insert 3 at index 3.
Key: 6
Hash value: h(6) = 6 mod 13 = 6. Insert 6 at index 6.
Key: 16
Hash value: h(16) = 16 mod 13 = 3. Index 3 is occupied. Use linear probing and insert 16 at index 4.
Key: 17
Hash value: h(17) = 17 mod 13 = 4. Index 4 is occupied. Use linear probing and insert 17 at index 5.
Key: 19
Hash value: h(19) = 19 mod 13 = 6. Index 6 is occupied. Use linear probing and insert 19 at index 7.
Final Hash Table
| Index | Value |
|---|---|
| 0 | – |
| 1 | – |
| 2 | – |
| 3 | 3 |
| 4 | 16 |
| 5 | 17 |
| 6 | 6 |
| 7 | 19 |
| 8 | – |
| 9 | – |
| 10 | 10 |
| 11 | – |
| 12 | – |
Summary
The final hash table after inserting all keys using linear probing is as follows:
#include <stdio.h> int main () { int n1, n2, max; printf ("Enter two positive integers: "); scanf ("%d %d", &n1, &n2); // maximum number between n1 and n2 is stored in max max = (n1> n2) ? n1: n2; while (1) { // Check if max is divisible by both n1 and n2 if ((max% n1 == 0)&& (max % n2 ==0)) { // If true, max is the LCM of n1 and n2 printf("The LCM of %d and %d is %d.", n1,n2,max); break; } ++max; } return 0; }
Sample I/O:
Enter two positive integers: 14 8
The LCM of 14 and 8 is 56.
=== Code Execution Successful ===
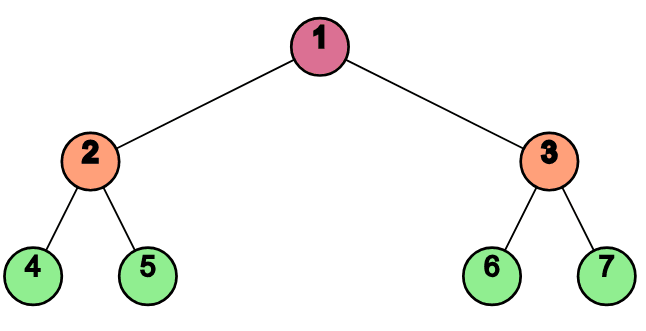 Adjacency List Representation
Adjacency List Representation| Vertex | Connected Vertices |
|---|---|
| 1 | 2, 3 |
| 2 | 4, 5 |
| 3 | 6, 7 |
| 4 | |
| 5 | |
| 6 | |
| 7 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Movies (mid, title, year)
People (pid, name)
Genres (gid, genre)
HasRole (pid, mid, role)
Has Genre (gid, mid)
Public class Class A {
Public void m1 () {}
Public void m2 (int i) {}
Public void m3 (int i) {}
Public static void m4 (int i) {}
Public class class B extends class A {
Public static void ml (int i) {}
Public void m2 (int i) {}
Public void m3 (string s) {}
Public static void m4 (int i) {}

[source:visual-paradigm.com]
Combined Bank, Assistant Programmer, 2023 (exam date: 09-06-2023)
- User Input = 50
- User Output = 40
- User Inquiries = 35
- User Files = 6
- External Interface = 4
Step 1:
As the complexity adjustment factor is average (given in the question), the scale is set to 3 for each factor.
F = 14 × 3 = 42
Step 2:
Calculate the Complexity Adjustment Factor (CAF) using the formula:
CAF = 0.65 + (0.01 × F)
Substitute F = 42:
CAF = 0.65 + (0.01 × 42) = 1.07
Step 3:
Calculate the Unadjusted Function Points (UFP) using the given values and the corresponding weights (average weighting factors):
UFP = (50 × 4) + (40 × 5) + (35 × 4) + (6 × 10) + (4 × 7)
UFP = 200 + 200 + 140 + 60 + 28 = 628
Step 4:
Calculate the Function Point (FP) using the formula:
FP = UFP × CAF
FP = 628 × 1.07 = 671.96
Final Answer:
The Function Point (FP) is: 671.96
Algorithm to Find the Smallest Element in an Array
START
Step 1 → Initialize an array A with given values.
Step 2 → Create a variable min_value and set it to a large number (e.g., infinity) or the first element of the array.
Step 3 → Loop through each element A[i] in the array starting from the first element.
Step 4 → For each element, check if A[i] is smaller than min_value.
Step 5 → If A[i] < min_value, update min_value to A[i].
Step 6 → Repeat Steps 4 and 5 until all elements have been checked.
Step 7 → Display min_value as the smallest element of the array.
STOP
- Page reference string: 1, 3, 0, 3, 5, 6, 3
- Number of page frames: 3
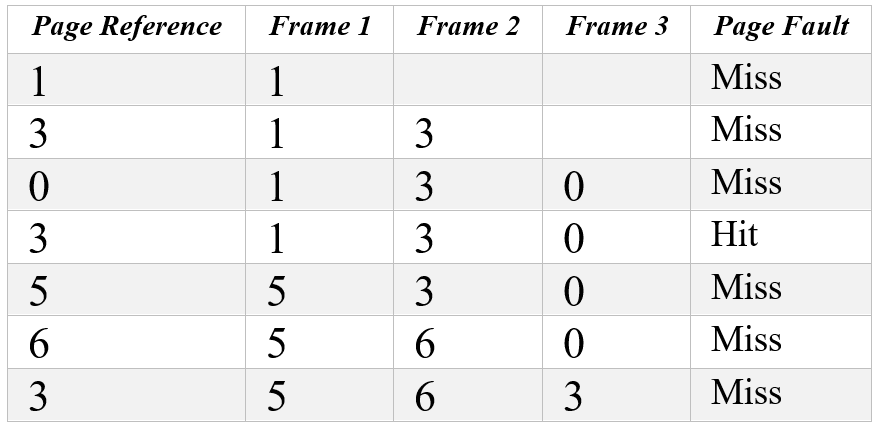 Explanation:
Explanation:- 1 causes a page fault as it’s not in memory, so it’s loaded into frame 1.
- 3 causes a page fault and is loaded into frame 2.
- 0 causes a page fault and is loaded into frame 3. All three frames are now full.
- 3 is already in memory, so no page fault occurs (Hit).
- 5 causes a page fault and replaces the oldest page in memory, which is 1.
- 6 causes a page fault and replaces the oldest page in memory, which is 3.
- 3 causes a page fault and replaces the oldest page in memory, which is 0.
- 6 Page Faults
Solution:
Step 1: Represent Data and Divisor in Polynomial Form
Data (11100):
x4 + x3 + x2
Divisor (1001):
x3 + 1
Step 2: Append Zeros to the Original Data
Since the divisor is 4 bits, we append 3 zeros to the original data (one less than the number of bits in the divisor). The new data is:
Data after appending zeros: 11100000
Step 3: Perform Binary Division
Now we divide the modified data 11100000 by the divisor 1001.
Division Process:
11111 ← Quotient —————————– 11100000 ← Dividend (data with zeros) 1001 ← Divisor ———————- 1110000 1001 —————- 111000 1001 ————— 11100 1001 ———— 1110 1001 ———— 111
Step 4: Determine the Transmitted Value
The remainder 111 is the CRC code. To get the transmitted value, append the remainder to the original data:
Original data: 11100 Remainder: 111
Transmitted Value: 11100111
SPCBL,Sub Assistant Programmer, 2022 (exam date: 15-01-2022)


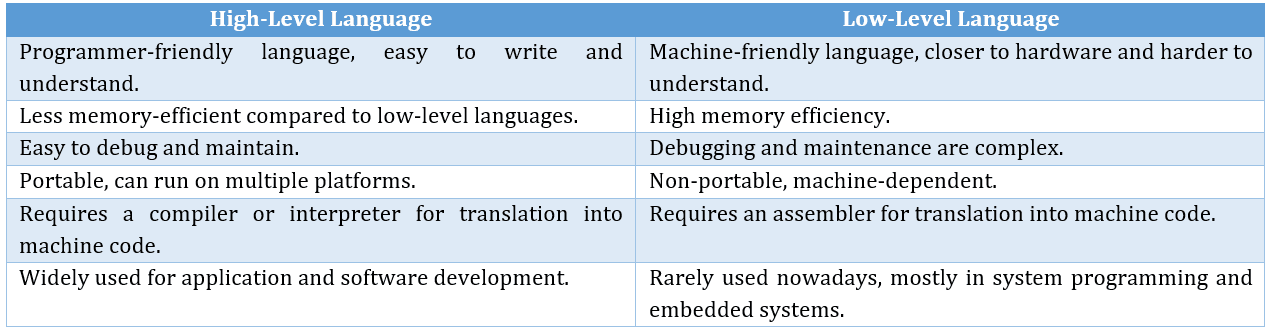
Examples:
- High-Level Languages: C, C++, Java, Python, etc.
- Low-Level Languages: Assembly Language, Machine Code.
Difference Between FIFO and LIFO in Data Structures: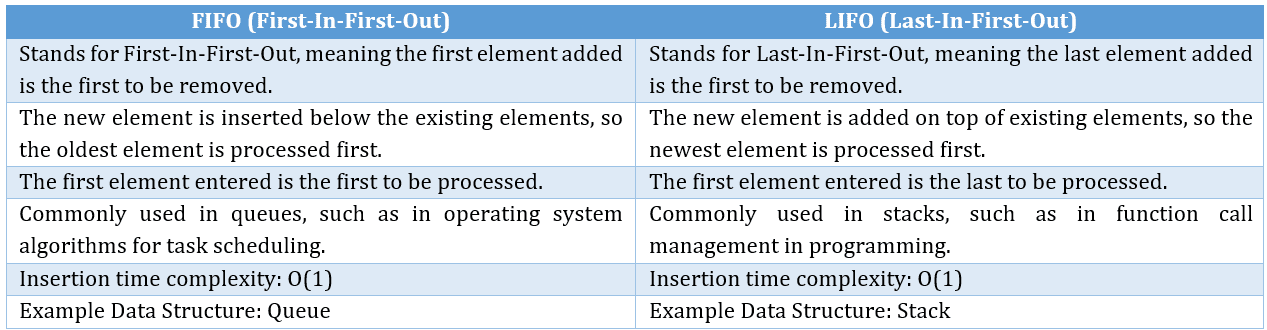
6 Bank and FI, Assistant Programmer, 2022 (exam date: 15-01-2022)
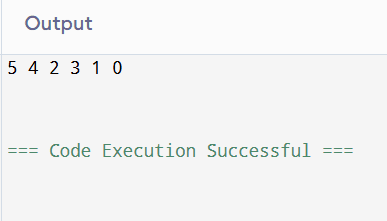
Input: 5 2, 5 0, 4 0, 4 1, 2 3, 3 1
Output: 5 4 2 3 1 0
#include <bits/stdc++.h>
using namespace std;
// Function to perform DFS and topological sorting
void topologicalSortUtil(int v, vector<vector<int>> &adj, vector<bool> &visited, stack<int> &st) {
// Mark the current node as visited
visited[v] = true;
// Recur for all adjacent vertices
for (int i : adj[v]) {
if (!visited[i])
topologicalSortUtil(i, adj, visited, st);
}
// Push current vertex to stack which stores the result
st.push(v);
}
vector<vector<int>> constructAdj(int V, vector<vector<int>> &edges) {
vector<vector<int>> adj(V);
for (auto it : edges) {
adj[it[0]].push_back(it[1]);
}
return adj;
}
// Function to perform Topological Sort
vector<int> topologicalSort(int V, vector<vector<int>> &edges) {
// Stack to store the result
stack<int> st;
vector<bool> visited(V, false);
vector<vector<int>> adj = constructAdj(V, edges);
// Call the recursive helper function for all vertices
for (int i = 0; i < V; i++) {
if (!visited[i])
topologicalSortUtil(i, adj, visited, st);
}
vector<int> ans;
// Append contents of stack
while (!st.empty()) {
ans.push_back(st.top());
st.pop();
}
return ans;
}
int main() {
int V = 6;
vector<vector<int>> edges = {
{2, 3}, {3, 1}, {4, 0}, {4, 1}, {5, 0}, {5, 2}
};
vector<int> ans = topologicalSort(V, edges);
for (int node : ans) {
cout << node << " ";
}
cout << endl;
return 0;
}
 Source:geeksforgeeks
Source:geeksforgeeks#include <bits/stdc++.h>
using namespace std;
// function to check if brackets are balanced
bool areBracketsBalanced(string expr)
{
stack s;
char x;
// Traversing the Expression
for (int i = 0; i < expr.length(); i++)
{
if (expr[i] == '(' || expr[i] == '[' || expr[i] == '{')
{
// Push the element in the stack
s.push(expr[i]);
continue;
}
// IF current current character is not opening
// bracket, then it must be closing. So stack
// cannot be empty at this point.
if (s.empty())
return false;
switch (expr[i]) {
case ')':
// Store the top element in a
x = s.top();
s.pop();
if (x == '{' || x == '[')
return false;
break;
case '}':
// Store the top element in b
x = s.top();
s.pop();
if (x == '(' || x == '[')
return false;
break;
case ']':
// Store the top element in c
x = s.top();
s.pop();
if (x == '(' || x == '{')
return false;
break;
}
}
// Check Empty Stack
return (s.empty());
}
// Driver code
int main()
{
string expr;
// Taking input from the user
cout << "Enter an expression: "; cin >> expr;
// Function call
if (areBracketsBalanced(expr))
cout << "Balanced\n";
else
cout << "Not Balanced\n";
return 0;
}

Source : GeeksforGeeks
#include <bits/stdc++.h>
using namespace std;
#define ll long long
bool isMountain(vector<ll> a) {
ll n = a.size();
if (n < 3)
return false;
ll i = 1;
// Increasing part
while (i < n && a[i] > a[i - 1]) {
i++;
}
// Peak cannot be first or last
if (i == 1 || i == n)
return false;
// Decreasing part
while (i < n && a[i] < a[i - 1]) {
i++;
}
return i == n;
}
int main() {
ll n;
cin >> n;
vector<ll> a(n);
for (ll i = 0; i < n; i++) {
cin >> a[i];
}
if (isMountain(a)) {
cout << "Mountain" << endl;
} else {
cout << "Not Mountain" << endl;
}
return 0;
}
 Source: Geeksforgeeks
Source: Geeksforgeeks
#include <bits/stdc++.h>
using namespace std;
#define N 6
// Define structure for Activity
struct Activity {
int start, finish;
};
// Function to compare two activities
bool Sort_activity(Activity s1, Activity s2) {
return (s1.finish < s2.finish); // Sort by finish time
}
// Function to print the maximum number of activities
void print_Max_Activities(Activity arr[], int n) {
// Sort activities based on finish time
sort(arr, arr + n, Sort_activity);
cout << "Following activities are selected: \n";
int i = 0;
cout << "(" << arr[i].start << ", " << arr[i].finish << ")\n";
// Select the next activity that starts after the last selected activity finishes
for (int j = 1; j < n; j++) {
if (arr[j].start >= arr[i].finish) {
cout << "(" << arr[j].start << ", " << arr[j].finish << ")\n";
i = j;
}
}
}
int main() {
Activity arr[N];
// Taking input from the user
for (int i = 0; i < N; i++) {
cout << "Enter the start and finish time for job " << i + 1 << " : ";
cin >> arr[i].start >> arr[i].finish;
}
// Function call to print the selected activities
print_Max_Activities(arr, N);
return 0;
}

#include <iostream>
#include <string>
using namespace std;
// Bank Management System using Class & Inheritance in C++
/*
1. Saving Account
2. Current Account
3. Account Creation
4. Deposit
5. Withdraw
6. Balance
*/
class account {
private:
string name;
int accno;
string atype;
public:
void getAccountDetails() {
cout << "\nEnter Customer Name : ";
cin >> name;
cout << "Enter Account Number : ";
cin >> accno;
cout << "Enter Account Type : ";
cin >> atype;
}
void displayDetails() {
cout << "\n\nCustomer Name : " << name;
cout << "\nAccount Number : " << accno;
cout << "\nAccount Type : " << atype;
}
};
class current_account : public account {
private:
float balance = 0;
public:
void c_display() {
cout << "\nBalance : " << balance;
}
void c_deposit() {
float deposit;
cout << "\nEnter amount to Deposit : ";
cin >> deposit;
balance = balance + deposit;
}
void c_withdraw() {
float withdraw;
cout << "\n\nBalance : " << balance;
cout << "\nEnter amount to be withdraw : ";
cin >> withdraw;
if (balance >= withdraw && balance > 1000) {
balance = balance - withdraw;
cout << "\nBalance Amount After Withdraw: " << balance;
} else {
cout << "\nInsufficient Balance";
}
}
};
class saving_account : public account {
private:
float sav_balance = 0;
public:
void s_display() {
cout << "\nBalance : " << sav_balance;
}
void s_deposit() {
float deposit, interest;
cout << "\nEnter amount to Deposit : ";
cin >> deposit;
sav_balance = sav_balance + deposit;
interest = (sav_balance * 2) / 100;
sav_balance = sav_balance + interest;
}
void s_withdraw() {
float withdraw;
cout << "\nBalance : " << sav_balance;
cout << "\nEnter amount to be withdraw : ";
cin >> withdraw;
if (sav_balance >= withdraw && sav_balance > 500) {
sav_balance = sav_balance - withdraw;
cout << "\nBalance Amount After Withdraw: " << sav_balance;
} else {
cout << "\nInsufficient Balance";
}
}
};
int main() {
current_account c1;
saving_account s1;
char type;
int choice;
cout << "\nEnter S for saving customer and C for current a/c customer : ";
cin >> type;
if (type == 's' || type == 'S') {
s1.getAccountDetails();
while (1) {
cout << "\nChoose Your Choice" << endl;
cout << "1) Deposit" << endl;
cout << "2) Withdraw" << endl;
cout << "3) Display Balance" << endl;
cout << "4) Display with full Details" << endl;
cout << "5) Exit" << endl;
cout << "Enter Your choice: ";
cin >> choice;
switch (choice) {
case 1:
s1.s_deposit();
break;
case 2:
s1.s_withdraw();
break;
case 3:
s1.s_display();
break;
case 4:
s1.displayDetails();
s1.s_display();
break;
case 5:
goto end;
default:
cout << "\n\nEntered choice is invalid, TRY AGAIN";
}
}
}
else if (type == 'c' || type == 'C') {
c1.getAccountDetails();
while (1) {
cout << "\nChoose Your Choice" << endl;
cout << "1) Deposit" << endl;
cout << "2) Withdraw" << endl;
cout << "3) Display Balance" << endl;
cout << "4) Display with full Details" << endl;
cout << "5) Exit" << endl;
cout << "Enter Your choice: ";
cin >> choice;
switch (choice) {
case 1:
c1.c_deposit();
break;
case 2:
c1.c_withdraw();
break;
case 3:
c1.c_display();
break;
case 4:
c1.displayDetails();
c1.c_display();
break;
case 5:
goto end;
default:
cout << "\n\nEntered choice is invalid, TRY AGAIN";
}
}
}
else {
cout << "\nInvalid Account Selection";
}
end:
cout << "\nThank You for Banking with us..";
return 0;
}
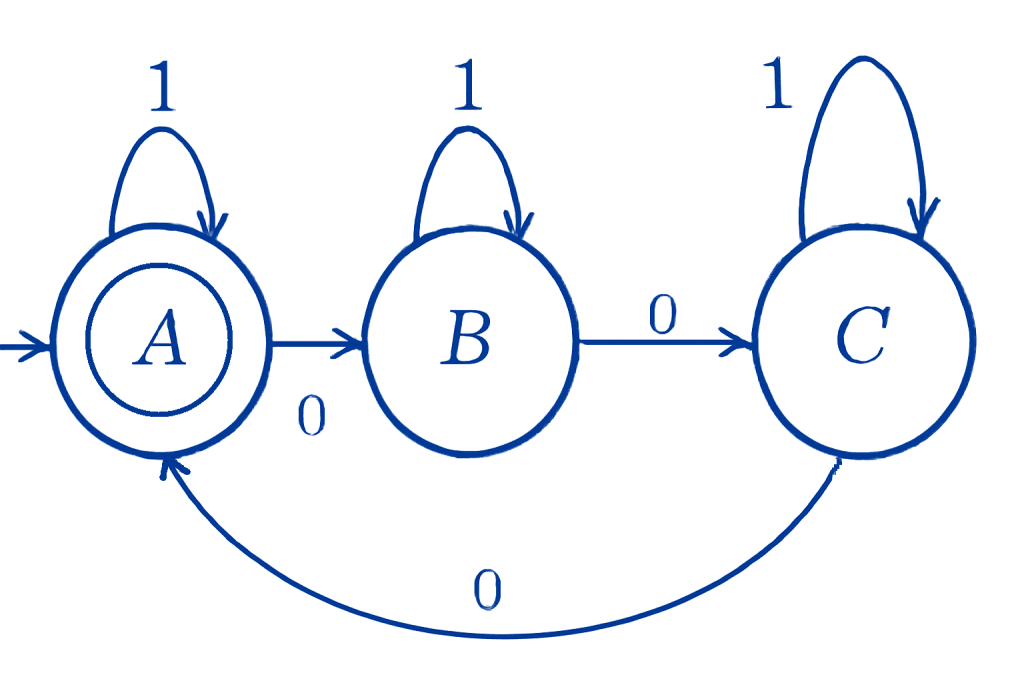 Transition Table:
Transition Table:| States | Input (0) | Input (1) |
|---|---|---|
| —> A * | B | A |
| B | C | B |
| C | A | C |