C Program to Swap Two Integers Using Call by Value
#include <stdio.h> void swap(int a, int b) { int temp = a; a = b; b = temp; printf("Inside swap function: a = %d, b = %d\n", a, b); } int main() { int x = 10, y = 20; printf("Before swap in main: x = %d, y = %d\n", x, y); swap(x, y); printf("After swap in main: x = %d, y = %d\n", x, y); // Values remain unchanged return 0; }
int a = 5, b= 18, c = 27,
a=b++ + ++c;
b = a++ - c --;
c= a++ + b --;
C++ Code Execution Explanation
Step-by-Step Execution
Initial values:
a = 5, b = 18, c = 27
Step 1: a = b++ + ++c;
• b++ → use 18, then b = 19
• ++c → increment first → c = 28, use 28
⇒ a = 18 + 28 = 46
Now: a = 46, b = 19, c = 28
Step 2: b = a++ - c--;
• a++ → use 46, then a = 47
• c-- → use 28, then c = 27
⇒ b = 46 – 28 = 18
Now: a = 47, b = 18, c = 27
Step 3: c = a++ + b--;
• a++ → use 47, then a = 48
• b-- → use 18, then b = 17
⇒ c = 47 + 18 = 65
Now: a = 48, b = 17, c = 65
Final Output
a = 48 b = 17 c = 65
Polymorphism means “many forms”.
It allows the same function name or operator to behave multiple form based on input or context.
Example:
- Sentence1: Driving a car;
- Sentence2: Driving a project;
Here same word “Driving” has different meanings.
Compile time polymorphism:
When a function call is resolved at compile time, it is called Compile-time Polymorphism. Here decision is made during compile time. Compile time polymorphism can be achieved by
- Function Overloading
- Operator overloading
Java program to demonstrate the compile time polymorphism
// Compile-time Polymorphism Example in Java
class Calculator {
// Method 1: Adds two integers
int add(int a, int b) {
return a + b;
}
// Method 2: Concatenates two strings
String add(String a, String b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calc = new Calculator();
// Calling add(int, int)
System.out.println("Sum of integers: " + calc.add(10, 20));
// Calling add(String, String)
System.out.println("Concatenation of strings: " + calc.add("Hello, ", "World!"));
}
}
Here, Method Overloading occurs when multiple methods in the same class have the same name but different parameter types or numbers.
The compiler decides which method to call at compile time, hence it’s called compile-time polymorphism.
Run time polymorphism:
When a function call is resolved at run time, it is called Run-time Polymorphism.
Achieved using:
- Inheritance
- Virtual Function Overriding
Java program to demonstrate the run time polymorphism
// Runtime Polymorphism Example in Java
class Animal {
void sound() {
System.out.println("Animal makes a sound");
}
}
class Dog extends Animal {
@Override
void sound() {
System.out.println("Dog barks");
}
}
public class Main {
public static void main(String[] args) {
// Reference of parent class, object of child class
Animal a = new Dog();
// Calls Dog's version of sound() at runtime
a.sound();
}
}
Runtime Polymorphism happens through method overriding —
when a subclass provides a specific implementation of a method already defined in its parent class.
The method to be executed is determined at runtime, not compile time.
The compiler knows a is of type Animal, but at runtime it sees that a actually refers to a Dog object, so it calls Dog’s sound() method
Given:
- (16A.6)16
- (72.3)8
(16A.6)16
Hex → 4-bit binary nibbles:
1 = 0001 6 = 0110 A = 1010 fraction 6 = 0110
(16A.6)16 = 101101010.0112
(72.3)8
Octal → 3-bit binary groups:
7 = 111 2 = 010 fraction 3 = 011
So (72.3)8 = 111010.0112
Binary addition
101101010.011 + 111010.011 ------------------ 110100100.11
Binary to Hexadecimal Conversion
Given Binary Number: 110100100.112
Group bits into 4-bit sets : 110100100.11 → 0001 1010 0100 .1100
Now convert each 4-bit group to hexadecimal:
- 0001 → 1
- 1010 → A
- 0100 → 4
- .1100 → .
C
Answer:
110100100.112 = (1A4.C)16
A universal gate is a logic gate that can be used to make any other type of logic gate or Boolean function. There are two universal gates — NAND and NOR.
Expression of XOR gate:
A’.B + A.B’
=[(A’.B + A.B’)’]’
=[ (A’.B)’ . (A.B’)’ ]’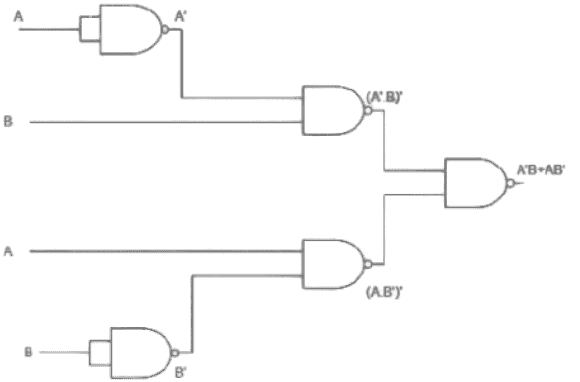
F = A'B'C + AB'C + ABC' + ABC
F = A’B’C + AB’C + ABC’ + ABC
Putting Function in k-map: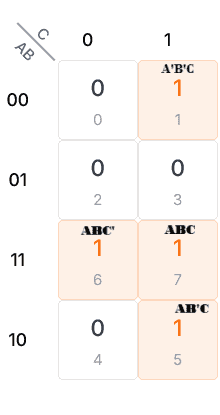
Grouping: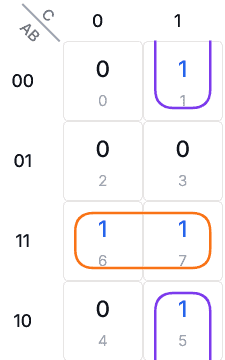
Final Simplification:
What will be the output for the following set operations?
(i) A∪B
(ii) A∩ B
(iii) A - B
(i) A ∪ B : {2, 3, 5, 7, 9, 11}
(ii) A ∩ B : {5, 9}
(iii) A – B : {2, 3}
2x1 + 4x2 - 6x3 = - 8
x1+3x2+x3 = 10
2x1-4x2 - 2x3 = - 12
Solve the following system using Gauss–Jordan method:
2x1 + 4x2 − 6x3 = −8
x1 + 3x2 + x3 = 10
2x1 − 4x2 − 2x3 = −12
Step 1: Augmented Matrix
\[
\left[
\begin{array}{ccc|c}
2 & 4 & -6 & -8 \\
1 & 3 & 1 & 10 \\
2 & -4 & -2 & -12
\end{array}
\right]
\]
Step 2: Swap R1 and R2
\[
\left[
\begin{array}{ccc|c}
1 & 3 & 1 & 10 \\
2 & 4 & -6 & -8 \\
2 & -4 & -2 & -12
\end{array}
\right]
\]
Step 3: R2 → R2 − 2R1,
R3 → R3 − 2R1
\[
\left[
\begin{array}{ccc|c}
1 & 3 & 1 & 10 \\
0 & -2 & -8 & -28 \\
0 & -10 & -4 & -32
\end{array}
\right]
\]
Step 4: R2 → (−1/2)R2
\[
\left[
\begin{array}{ccc|c}
1 & 3 & 1 & 10 \\
0 & 1 & 4 & 14 \\
0 & -10 & -4 & -32
\end{array}
\right]
\]
Step 5: R1 → R1 − 3R2,
R3 → R3 + 10R2
\[
\left[
\begin{array}{ccc|c}
1 & 0 & -11 & -32 \\
0 & 1 & 4 & 14 \\
0 & 0 & 36 & 108
\end{array}
\right]
\]
Step 6: R3 → (1/36)R3
\[
\left[
\begin{array}{ccc|c}
1 & 0 & -11 & -32 \\
0 & 1 & 4 & 14 \\
0 & 0 & 1 & 3
\end{array}
\right]
\]
Step 7: R1 → R1 + 11R3,
R2 → R2 − 4R3
\[
\left[
\begin{array}{ccc|c}
1 & 0 & 0 & 1 \\
0 & 1 & 0 & 2 \\
0 & 0 & 1 & 3
\end{array}
\right]
\]
Final Solution:
\[
x_1 = 1,\quad x_2 = 2,\quad x_3 = 3
\]
From 10 different types of cookies, selecting 6 different types to make a box can indeed be done in
10C6=210 ways.
i) Write a formula to calculate the address of the element A [1] [1], where i is row and j is column.
ii) What will be the address of the element if f = 2 and 3 in a 5 x 8 array.
iii) Transform the equation if the array is organized in the column-major way.
Consider a 2-D array A stored using row-major organization.
Base address = 1000
Size of each element = 4 bytes
i) Formula to calculate the address of element A[i][j] (Row-Major Order):
In row-major organization, elements of a two-dimensional array are stored row by row in contiguous memory locations.
Formula:
Address(A[i][j]) = Base Address + { ( i × Number of Columns + j ) × Size of each element }
ii) Address of the element when i = 2 and j = 3 in a 5 × 8 array:
Number of columns = 8
Base address = 1000
Element size = 4 bytes
Address = 1000 + { (2 × 8 + 3) × 4 }
Address = 1000 + (19 × 4)
Address = 1000 + 76
Address = 1076
iii) Formula if the array is organized in Column-Major Order:
In column-major organization, elements are stored column by column in memory.
Formula:
Address(A[i][j]) = Base Address + { ( j × Number of Rows + i ) × Size of each element }
(a+b)/(a*b-c)+d
(+)
/ \
(/) d
/ \
(+) (-)
/ \ / \
a b (*) c
/ \
a b
| 0 | 1 | 2 | 3 | 4 | 5 |
| 7 | 2 | 9 | 4 | 5 | 3 |
Given Array: 7, 2, 9, 4, 5, 3
First, represent the array as a Complete Binary Tree:
7
/ \
2 9
/ \ /
4 5 3
Step 1: Start Heapify from the Bottom Non-Leaf Node
Compare node 9 with its child 3.
Since 9 > 3, swap them.
7
/ \
2 3
/ \ /
4 5 9
Step 2:
Compare node 2 with its children 4 and 5.
Since 2 < 4 and 2 < 5, no swap is required.
7
/ \
2 3
/ \ /
4 5 9
Step 3:
Compare root node 7 with its children 2 and 3.
The smallest child is 2, and since 7 > 2, swap them.
2
/ \
7 3
/ \ /
4 5 9
Step 4:
Now compare node 7 with its children 4 and 5.
The smallest child is 4, and since 7 > 4, swap them.
2
/ \
4 3
/ \ /
7 5 9
Final Min-Heap:
The heap now satisfies the min-heap property.
2
/ \
4 3
/ \ /
7 5 9
Final Min-Heap Array Representation: 2, 4, 3, 7, 5, 9
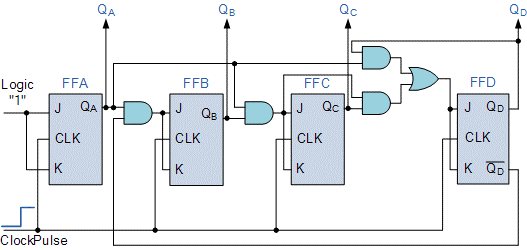
Difference Between Microprocessor and Microcontroller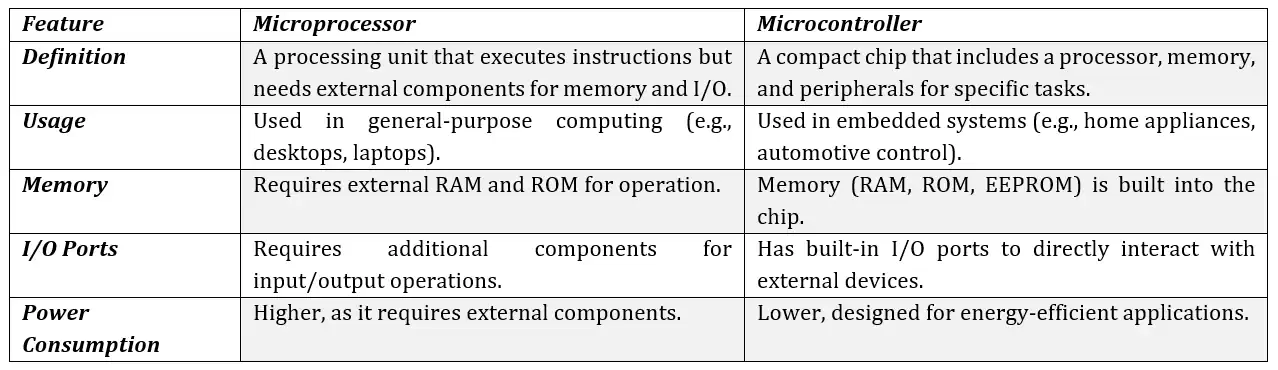
(i) Immediate
(ii) Direct
(ii) Indirect
(iv) Register
(v) Indexed
1
1
for i in N:
for j in M:
print (i, j)Code Snippet:for i in N:
for j in M:
print(i, j)
Time Complexity:
– The outer loop runs len(N) times.
– The inner loop runs len(M) times for each iteration of the outer loop.
– Total operations = len(N) * len(M).
O(N * M)
Space Complexity:
– Only loop variables i and j are used.
– No extra memory is required.
O(1)
for example -
Coins = {1, 2, 5}
Amount = 11
Output = 3,
explanation: Coin 5+ 5 + 1 can make 11.
Required Properties for Dynamic Programming:
1. Optimal Substructure: The solution to a problem can be constructed from solutions of its subproblems.
2. Overlapping Subproblems: The problem can be broken down into subproblems which are solved multiple times.
Problem: Given a set of coins and an amount, find the minimum number of coins required to make the amount. If it is not possible, return -1.
Example:
Coins = {1, 2, 5}
Amount = 11
Output = 3
Explanation: 5 + 5 + 1 = 11
Dynamic Programming Algorithm (Bottom-Up Approach):
function coinChange(coins, amount):
dp = array of size (amount + 1) filled with (amount + 1)
dp[0] = 0 # 0 coins needed to make amount 0
for i from 1 to amount:
for coin in coins:
if coin <= i:
dp[i] = min(dp[i], dp[i – coin] + 1)
if dp[amount] > amount:
return -1
else:
return dp[amount]
Explanation:
– Initialize a dp array where dp[i] stores minimum coins to make amount i.
– Loop through all amounts from 1 to target amount.
– For each coin, update dp[i] if using that coin reduces the number of coins.
– If dp[amount] is still larger than amount, the amount cannot be formed, return -1.
1
Deadlock in an operating system occurs when two or more processes are stuck and cannot proceed because they are each waiting for a resource that another process holds. Essentially, the processes are in a “waiting loop,” and none can continue because they are all waiting for each other to release resources.
Example: Imagine two people on a narrow staircase. One is going up, and the other is going down. Neither can move because the other person is blocking their path, and neither is willing to back up. They are stuck, waiting for the other to move first, which will never happen.
Necessary condition for occuring deadlock / Coffman Conditions
For a deadlock to happen, four conditions must all be true at the same time. These are called the Coffman conditions, named after the researchers who explained them.
- Mutual Exclusion: A resource can only be used by one process at a time. If a process is using a resource, no other process can use it until the first process releases it.
- Hold and Wait: A process is holding at least one resource and is waiting for additional resources that are currently held by other processes.
- No Preemption: Resources cannot be taken away from a process forcefully. A process can only release resources voluntarily when it is no longer needed.
Circular Wait: A cycle exists where each process in the cycle is waiting for a resource that the next process holds. For example, Process A is waiting for Process B’s resource, Process B is waiting for Process C’s resource, and Process C is waiting for Process A’s resource.
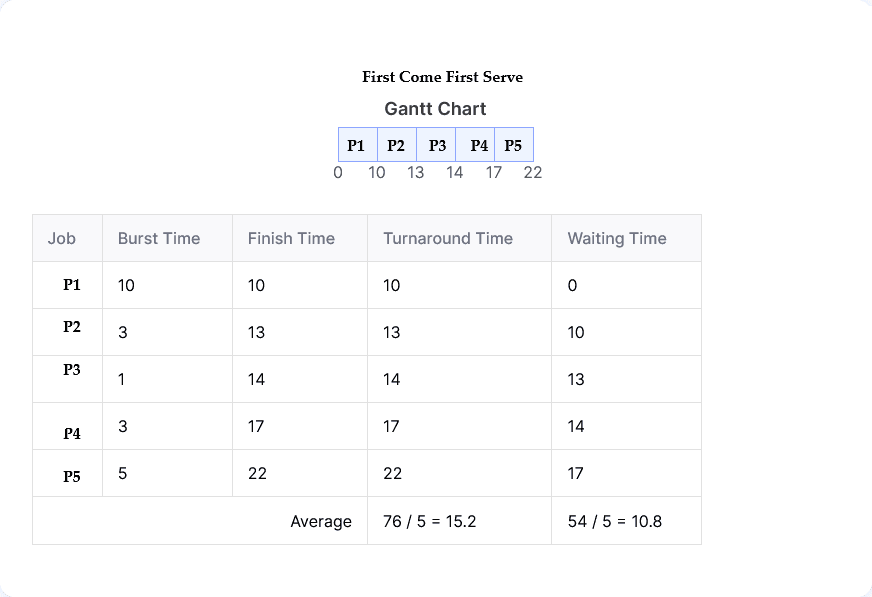
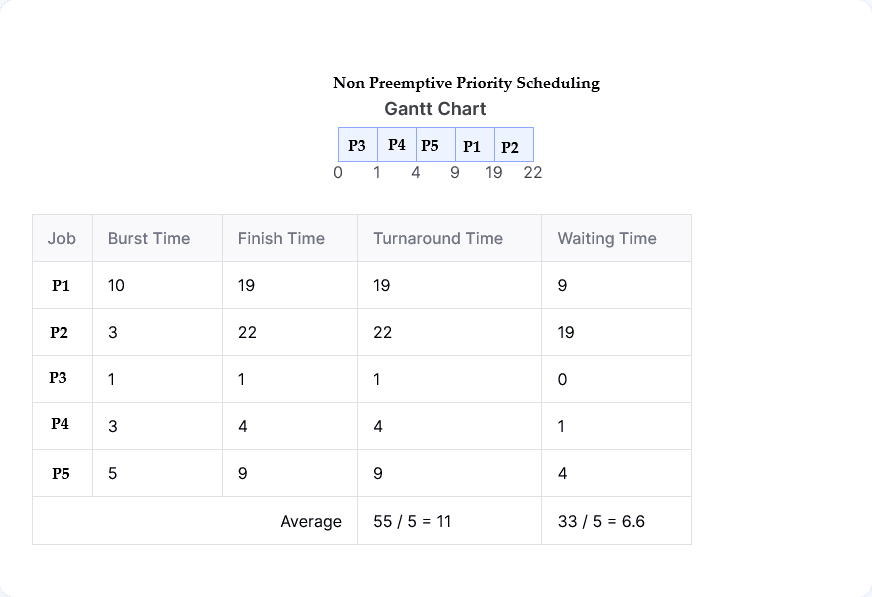
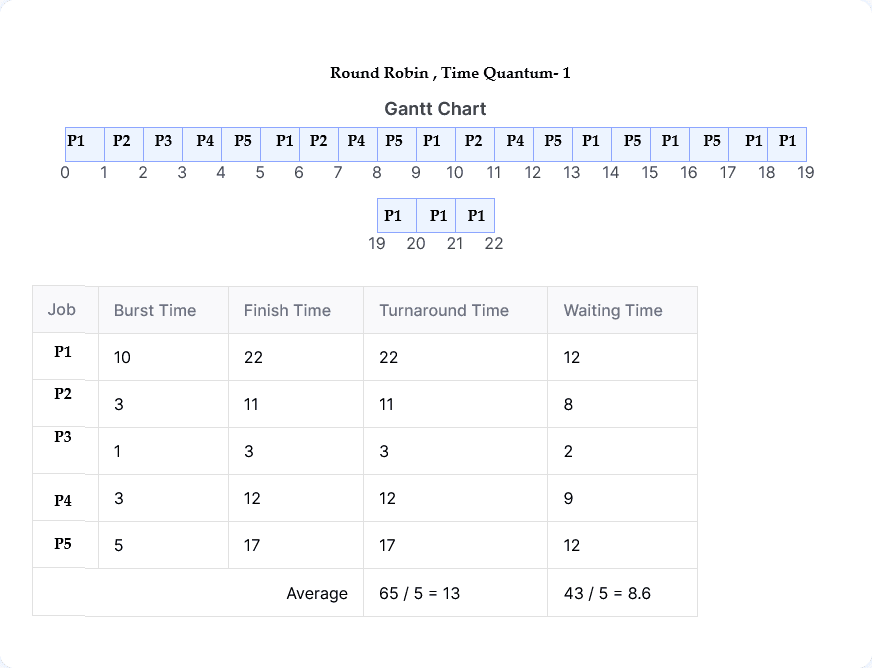
| Process | Burst Time (ms) | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 3 | 4 |
| P3 | 1 | 1 |
| P4 | 3 | 2 |
| P5 | 5 | 2 |
(i) FCFS
(ii) Non-preemptive (low value means higher priority)
(iii) RR (Quantum value =1)
Trigger Example
The following trigger stores the current timestamp in another table whenever an INSERT or UPDATE occurs:
CREATE TRIGGER trg_log_time
AFTER INSERT OR UPDATE ON MainTable
FOR EACH ROW
BEGIN
INSERT INTO LogTable (id, action_time)
VALUES (NEW.id, CURRENT_TIMESTAMP);
END;
employee (id, name, salary),
equipment (id, name, price), hire (employee-id, equipment-id),
(i) Draw the ER diagram for the above.
(ii) Write the SQL query to show the name of the employee who hired the maximum number of equipment.
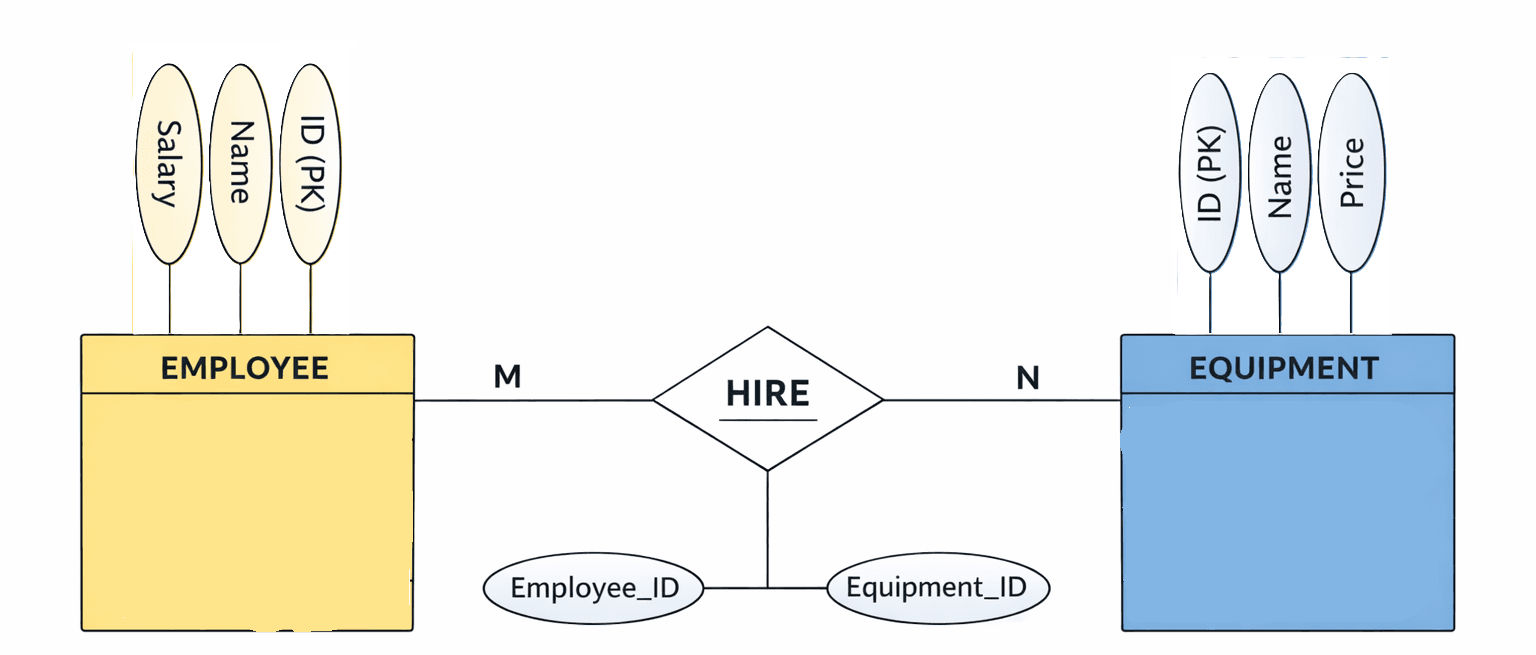
(ii)
SELECT e.name FROM employee e, hire h WHERE e.id = h.employee_id GROUP BY e.id, e.name HAVING COUNT(h.equipment_id) = ( SELECT MAX(cnt) FROM ( SELECT COUNT(equipment_id) AS cnt FROM hire GROUP BY employee_id ) t );
2NF, 3NF and BCNF.
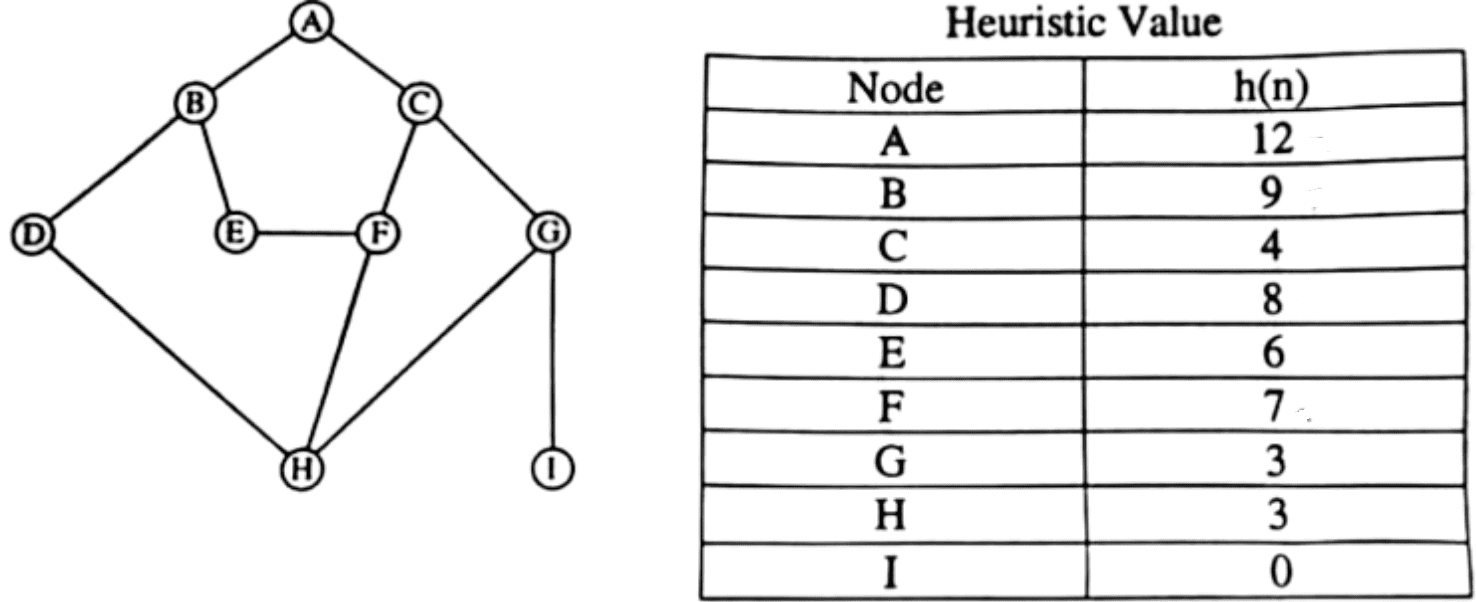
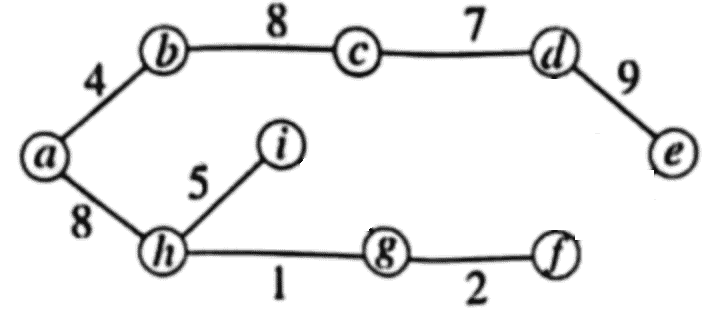
Consider the following tree and the heuristic value h(n) at each node of the tree as Heuristic Value shown in the table.If A is the start node and I is the destination node, explain how Best first search algorithm can be used to find the destination node. Moreover, show the path to the destination. 4