[source: Medium.Com]
#include <stdio.h>
// Recursive function to find GCD
int gcd(int a, int b) {
if (b == 0)
return a;
else
return gcd(b, a % b);
}
int main() {
int num1 = 96, num2 = 36;
int result = gcd(num1, num2);
printf("GCD of %d and %d is %d\n", num1, num2, result);
return 0;
}We apply the recursive formula:
gcd(96, 36)
→ 96 % 36 = 24
→ call gcd(36, 24)
gcd(36, 24)
→ 36 % 24 = 12
→ call gcd(24, 12)
gcd(24, 12)
→ 24 % 12 = 0
→ call gcd(12, 0)
gcd(12, 0)
→ Base case reached
→ return 12
Final Answer:
GCD(96, 36) = 12
[Source: scaler.com1 scaler.com2]
[source : lp.com ,
theknowledgeacademy]
4-bit 2’s Complement Combinational Logic Circuit
Concept:
- 2’s complement of a binary number is found by inverting all bits and then adding 1.
- For a 4-bit input A B C D, output will be W X Y Z.
Truth Table:
| Input ABCD | 2’s Complement WXYZ |
|---|---|
| 0000 | 0000 |
| 0001 | 1111 |
| 0010 | 1110 |
| 0011 | 1101 |
| 0100 | 1100 |
| 0101 | 1011 |
| 0110 | 1010 |
| 0111 | 1001 |
| 1000 | 1000 |
| 1001 | 0111 |
| 1010 | 0110 |
| 1011 | 0101 |
| 1100 | 0100 |
| 1101 | 0011 |
| 1110 | 0010 |
| 1111 | 0001 |
Necessary Boolean Equations:
- Z = D
- Y = C ⊕ D
- X = B ⊕ (C + D)
- W = A ⊕ (B + C + D)
🎥Reference Video: Design a 4-bit Circuit that takes the 2’s Complement [Credit: EE Vibes]
Given:
- f(x) = cos x − x
- Initial value, x₀ = 0.5
Formula:
- xn+1 = xn − f(xn) / f'(xn)
Derivative:
- f(x) = cos x − x
- f'(x) = −sin x − 1
Iteration 1:
- x₀ = 0.5
- f(0.5) = cos(0.5) − 0.5 = 0.3776
- f'(0.5) = −sin(0.5) − 1 = −1.4794
- x₁ = 0.5 − (0.3776 / −1.4794)
- x₁ = 0.7552
Iteration 2:
- x₁ = 0.7552
- f(0.7552) = cos(0.7552) − 0.7552 = −0.0271
- f'(0.7552) = −sin(0.7552) − 1 = −1.6855
- x₂ = 0.7552 − (−0.0271 / −1.6855)
- x₂ = 0.7391
Iteration 3:
- x₂ = 0.7391
- f(0.7391) ≈ 0
- So, root ≈ 0.7391
The root of f(x) = cos x − x is approximately 0.7391
[source : medium.com]
Given Frequencies:
- A = 5
- B = 9
- C = 12
- D = 13
- E = 16
- F = 45
Step-by-Step Huffman Tree Construction:
- Step 1: Combine A(5) + B(9) = 14
- Step 2: Combine C(12) + D(13) = 25
- Step 3: Combine 14 + E(16) = 30
- Step 4: Combine 25 + 30 = 55
- Step 5: Combine F(45) + 55 = 100
Huffman Tree:
(100)
/ \
F:45 (55)
/ \
(25) (30)
/ \ / \
C:12 D:13 (14) E:16
/ \
A:5 B:9
Code Direction:
- Left edge = 0
- Right edge = 1
Huffman Codes:
- F = 0
- C = 100
- D = 101
- A = 1100
- B = 1101
- E = 111
Average Code Length Calculation:
- Total frequency = 5 + 9 + 12 + 13 + 16 + 45 = 100
- Average Code Length = Σ(frequency × code length) / Total frequency
- = (45×1 + 12×3 + 13×3 + 5×4 + 9×4 + 16×3) / 100
- = (45 + 36 + 39 + 20 + 36 + 48) / 100
- = 224 / 100
- = 2.24 bits/symbol
Final Answer:
- Average Code Length = 2.24 bits/symbol
Infix: (A+B) * (C-D) / E
Postfix: AB+CD-*E/
| Sr No | Expression | Stack | Postfix |
|---|---|---|---|
| 0 | ( | ( | |
| 1 | A | ( | A |
| 2 | + | ( + | A |
| 3 | B | ( + | A B |
| 4 | ) | A B + | |
| 5 | * | * | A B + |
| 6 | ( | * ( | A B + |
| 7 | C | * ( | A B + C |
| 8 | – | * ( – | A B + C |
| 9 | D | * ( – | A B + C D |
| 10 | ) | * | A B + C D – |
| 11 | / | / | A B + C D – * |
| 12 | E | / | A B + C D – * E |
| 13 | A B + C D – * E / |
Given Array:
- [45, 15, 60, 30, 75, 20]
Assumption:
- Here, the last element is selected as pivot.
Step 1: First Partition
- Array = [45, 15, 60, 30, 75, 20]
- Pivot = 20
- Elements smaller than 20: 15
- Elements greater than 20: 45, 60, 30, 75
- After partition: [15, 20, 60, 30, 75, 45]
Step 2: Sort Right Sub-array
- Right sub-array = [60, 30, 75, 45]
- Pivot = 45
- Elements smaller than 45: 30
- Elements greater than 45: 60, 75
- After partition: [30, 45, 75, 60]
- Full array becomes: [15, 20, 30, 45, 75, 60]
Step 3: Sort Right Sub-array Again
- Right sub-array = [75, 60]
- Pivot = 60
- Elements smaller than 60: none
- Elements greater than 60: 75
- After partition: [60, 75]
Final Sorted Array:
- [15, 20, 30, 45, 60, 75] ✅
[Source : geeksforgeeks]
[Source : geeksforgeeks]
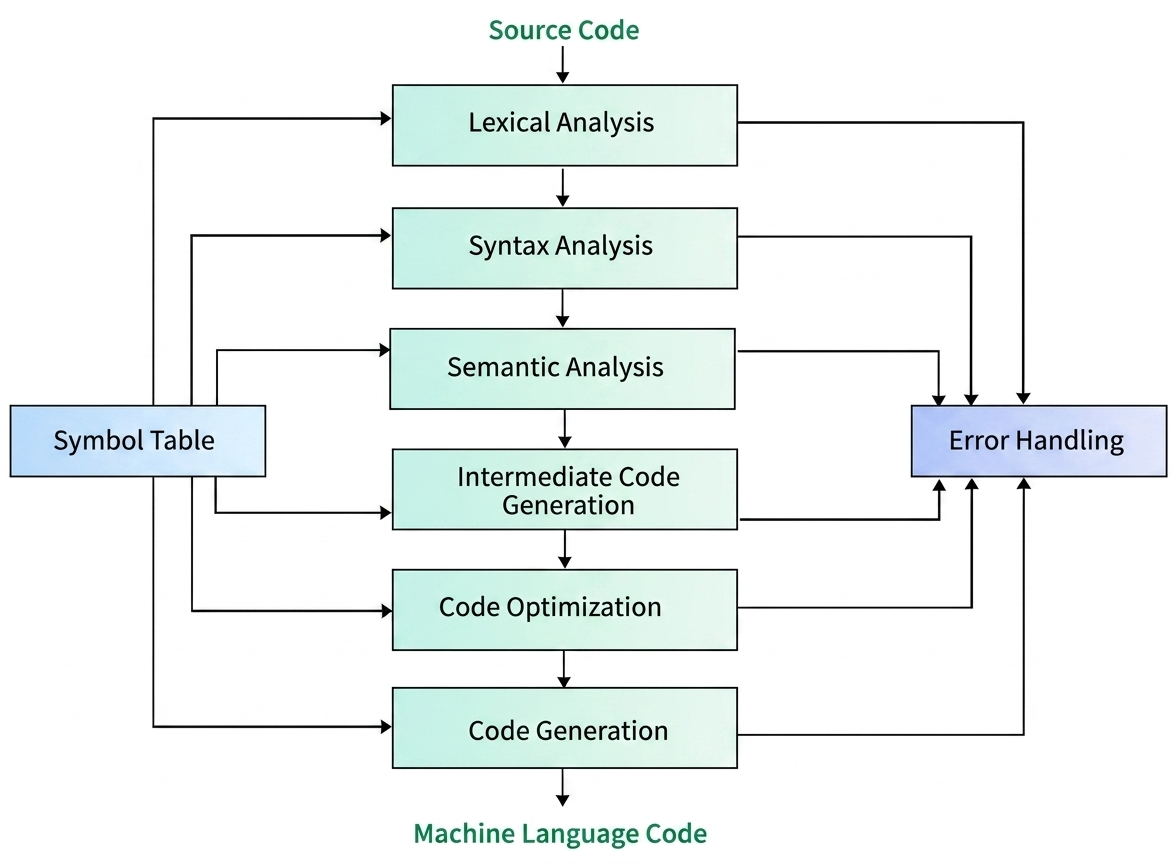
Given:
L1 hit ratio (H1) = 0.9
L1 access time (T1) = 1 ns
L2 hit ratio (H2) = 0.8
L2 access time (T2) = 10 ns
Main memory access time (Tm) = 80 ns
Formula:
EMAT = H1T1 + (1 − H1) [ H2(T1 + T2) + (1 − H2)(T1 + T2 + Tm) ]
Calculation:
L1 hit time = 0.9 × 1 = 0.9 ns
L1 miss = 0.1
L2 hit time = 0.1 × 0.8 × (1 + 10) = 0.08 × 11 = 0.88 ns
L2 miss time = 0.1 × 0.2 × (1 + 10 + 80) = 0.02 × 91 = 1.82 ns
Total EMAT:
EMAT = 0.9 + 0.88 + 1.82 = 3.6 ns
Final Answer: EMAT = 3.6 ns